the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 18 Aug 2025
| 18 Aug 2025
Leveraging snow probe data, lidar, and machine learning for snow depth estimation in complex-terrain environments
Dane Liljestrand
Ryan Johnson
Bethany Neilson
Patrick Strong
Elizabeth Cotter
The majority of the water supply for many western US states is derived from seasonal snowmelt in mountainous regions. This study aims to generate basin-scale snow depth estimates using a multistep, Gaussian-based machine learning model that combines snow probe depth measurements with static lidar terrain features from a single snow-free date, enabling rapid, high-resolution estimation at low institutional cost. We focus on reducing personnel danger by modifying the algorithm to minimize the exposure of field sample collectors to avalanche-prone terrain. Using snow observations taken solely within a subbasin (∼ 9 km2) of a larger basin (∼ 70 km2), a basin-scale snow depth estimate is modeled for a given date throughout the snow season. Results show that a small number of observations (i.e., 10) within a subbasin can realize snow depth across the greater basin with high accuracy, with a root mean squared error (RMSE) of 0.37 m and Kling–Gupta efficiency (KGE) of 0.59 when compared to lidar snow depth distribution. We test the universality of the algorithm by modeling multiple subbasins of differing spatial characteristics and find similar results. The algorithm shows consistent performance across subbasins with varying spatial characteristics and maintains accuracy even when high-risk avalanche areas are excluded from the training data. This method exhibits a potential for citizen-scientist data to safely provide gridded modeled snow depth across different spatial ranges in snow-covered basins.
- Article
(3245 KB) - Full-text XML
-
Supplement
(506 KB) - BibTeX
- EndNote




Seasonal snow-derived water is a critical component of the water supply in mountainous basins and connected downstream regions (Painter et al., 2016; Bales et al., 2006). More than one-sixth of the world’s population is in a region where snowmelt accounts for at least 50 % of the annual runoff (Barnett et al., 2005). In the western United States, where the economic value of the yearly snowpack has been estimated to be on the order of a trillion US dollars (Sturm et al., 2017), many states’ water supply is nearly entirely dependent on mountain snowpack. Climate variability is pressuring this water supply, and over the last century, much of the West has observed decreasing available water from snow, and more rapidly over the past 20 years (Mote et al., 2005, 2018).
Increasing populations and changing climate dynamics outline the crucial endeavor of accurately measuring available seasonal snow for water resource management. Acknowledging this need, the US Natural Resource Conservation Service has installed and operates nearly 900 snow telemetry (SNOTEL) in situ monitoring sites throughout the western US (NRCS, 2022). These stations maintain the largest near-instantaneous monitoring network of snow depth and other environmental variables, forming the foundation for many water resource management forecasts throughout the country. Despite the broad network, the full spatial representation of mountainous regions remains a problem. Within the contiguous US, there is, on average, one SNOTEL site per approximately 4000 km2 of potential snow-covered area (Rutgers University Global Snow Lab, 2023). The low density of sites highlights the need for additional observations or techniques to produce an accurate and continuous snowpack estimate.
Accurately representing basin-scale (30–200 km2) snowpack is challenging due to scale and geographic heterogeneity. A single basin can exhibit broad slope, elevation, and land cover differences, all influencing snow distribution. While SNOTEL serves as the largest in situ dataset in the US, studies have found that station measurements often did not align with mean values from surrounding areas and vary in their broader accuracy during accumulation and melt seasons (Molotch and Bales, 2005; Lundquist et al., 2005; Meromy et al., 2013; Herbert et al., 2024). Heterogeneity in snowpack arises from interactions between the landscape features, wind, and forest canopy, among other factors, with varying effects across scales (Clark et al., 2011). While small-scale processes like wind and radiative fluxes dominate at the hillslope scale (1–100 m), elevation becomes crucial at larger scales. Often, snow depth may be well-represented by a Gaussian distribution. However, the distribution is commonly skewed during accumulation and melt periods, in wind-affected terrain, or when no-snow areas are present, and a static probability density should not always be assumed (He et al., 2019; Ohara et al., 2024). The multitude of factors affecting snow depth at varying scales make it challenging to universally identify the most relevant features for accurate snow depth estimation and complicate representative sampling.
When attempting to quantify a snowpack through measurement locations – whether for permanent instrumentation or one-time sampling – it is important to optimize the placement to represent various physical features effectively. Pioneering work on optimizing snow measurement networks was performed by Galeati et al. (1986), who applied a multivariate statistical methodology with the aim of selecting a reduced number of monitoring stations within the Italian Alps monitoring network. The study applied a clustering technique on station observations and performed principal component analysis to determine insignificant or redundant stations. Their results showed that 30 % of the network stations could be removed and suitably replaced with observations from neighboring stations.
While early studies focused on optimizing existing networks, recent research has enhanced network efficiency by optimizing measurement locations before installation. These studies have shown that fewer, strategically placed sensors can reduce modeled snow error in a relatively small, monitored catchment (Collados-Lara et al., 2020; Kerkez et al., 2012; López-Moreno et al., 2011; Oroza et al., 2016; Saghafian et al., 2016; Welch et al., 2013). Despite these advancements, challenges remain in the resource-intensive task of physically locating and installing measurement stations, as well as the fact that static locations may not be ideal throughout different phases of the snow cycle. Additionally, the representativeness of point measurements over larger areas remains uncertain, and the extent to which these measurements accurately reflect snowpack conditions beyond their immediate vicinity is unknown.
Remote sensing products such as the Snow Data Assimilation System (SNODAS) offer an alternative to ground-based measurement networks by providing snowpack estimates over large areas using a combination of ground-based, airborne, and satellite observations (Barrett, 2003). However, SNODAS and similar products have their limitations, including a relatively coarse spatial resolution (1 km), which can miss fine-scale variability in snow depth, and inaccuracies in complex terrains or densely forested areas where ground-based observations are sparse (Clow et al., 2012).
Aerial light detection and ranging (lidar) has improved the feasibility of high-resolution capture of snow depth data without relying on ground-based measurement stations and the spatial constraints of traditional remote sensing products. By subtracting a baseline snow-free DEM from a lidar-derived snow-on DEM, the resulting difference between the two precisely measures the snow depth across the surveyed area (Deems et al., 2013). While lidar is particularly effective in regions with deeper, uniform snowpack, it has limitations, and performance diminishes under canopy interactions and in shallower snow regions (Harder et al., 2016). The financial costs of lidar instrumentation and acquisition, especially for repeat or large-area surveys, also pose a significant constraint. Additionally, flying during adverse weather conditions makes monitoring snowpack changes throughout the season difficult. By contrast, lidar surveys of snow-free terrain, which are less temporally constrained, can be conducted during the non-snow season to capture static surface features. To enhance the accuracy of regional snowpack estimates, physiographic surface data from snow-free lidar scans can be combined with on-ground point measurements of snow. This technique integrates the detailed localized data from ground observations with the broad coverage offered by lidar. When optimally located, the point measurements may help refine snow depth estimates and improve the overall understanding of snowpack variability (Oroza et al., 2016).
An increasing number of recreationists and citizen scientists in remote snow-covered environments provides opportunities for numerous low-institutional-cost point measurements across different spatial and temporal ranges. On-ground snow depth data reported by such users via a mobile app platform (details at communitysnowobs.org) provide a novel data source for scientists and water managers to supplement higher-cost collection methods (Crumley et al., 2021). However, access to remote sampling locations often can require a researcher or recreationist to travel in, under, or above avalanche terrain, exposing them to a potentially fatal outcome (CAIC, 2022). Nearly all avalanche fatalities occur in remote, uncontrolled terrain, with the majority occurring from individuals caught in a self-triggered avalanche or one caused by another member of their group (Techel et al., 2016; Schweizer and Lütschg, 2001). Thus, it is imperative to develop sampling methods in remote regions that address and protect the safety of the individuals collecting data.
For snow sampling and modeling, snow water equivalent (SWE) is the most critical variable for predicting runoff and downstream hydrological processes (Clow et al., 2012). Because SWE is a function of both snow depth and density, improved estimates of either parameter can enhance SWE accuracy. Of these, snow depth is more readily and repeatedly measured during single-day field surveys and is also the primary variable captured by lidar. In contrast, snow density is more difficult to measure and requires more time and effort. Where available, snow surveys provide in situ point estimates of snow density, while parameterized models or generalized classifications provide more spatially extensive estimates. By combining high-resolution snow depth data with modeled or interpolated density values, researchers may generate more accurate spatial SWE estimates (Jonas et al., 2009; Sturm et al., 2010; Sturm and Liston, 2021).
In this study, we utilize a multistep, Gaussian-based machine learning model to investigate the feasibility of generating rapid, high-resolution, basin-scale snow depth estimates by combining snow probe depth observations with (static) lidar terrain features with a built-in reduction in personnel danger from avalanche exposure. Within this work, we address three main objectives: (i) validate the model's universality by sampling separate subbasins with differing spatial characteristics using a limited number of in situ measurements to estimate snow depth and evaluate the performance in varied, complex terrain; (ii) investigate the accuracy of basin-scale estimation beyond a smaller sampling domain with sparse sampling locations both within and outside of the modeled basin; and (iii) determine if estimation accuracy is affected by the exclusion of high-avalanche-risk terrain when selecting measurement locations.
2.1 Study area description
We focus our study on the Franklin Basin region at the Utah–Idaho border, which encompasses the headwaters of the Logan River and its upper tributaries. The Logan River supplies the major population of the Cache Valley, with an average annual flow of approximately 6.5 m3 s−1 at the mouth of the canyon and a snowmelt-dominated hydrograph that delivers peak flow in the spring (Neilson et al., 2020). The limits of the study span an area within the Bear River Range of the greater Western Rocky Mountains (Fig. 1). The study basin's elevation ranges from 2115 to 2940 m, with a mean of 2530 m, and it is predominantly easterly facing. It is vegetated primarily with forest, range land, and alpine environments at upper elevations. The geology of the basin is characterized primarily by limestone and dolomite (Dover, 1995). Little development exists within this region, with the primary infrastructure consisting of a local ski resort, forest access roads, and seasonal homes. We select three subbasins to study and compare with the overall extent of Franklin Basin: Hell’s Kitchen Canyon, which neighbors the larger basin to the south, and Boss Canyon and Peterson Hollow, both located centrally within Franklin Basin. All three sub-watersheds drain to the Logan River.
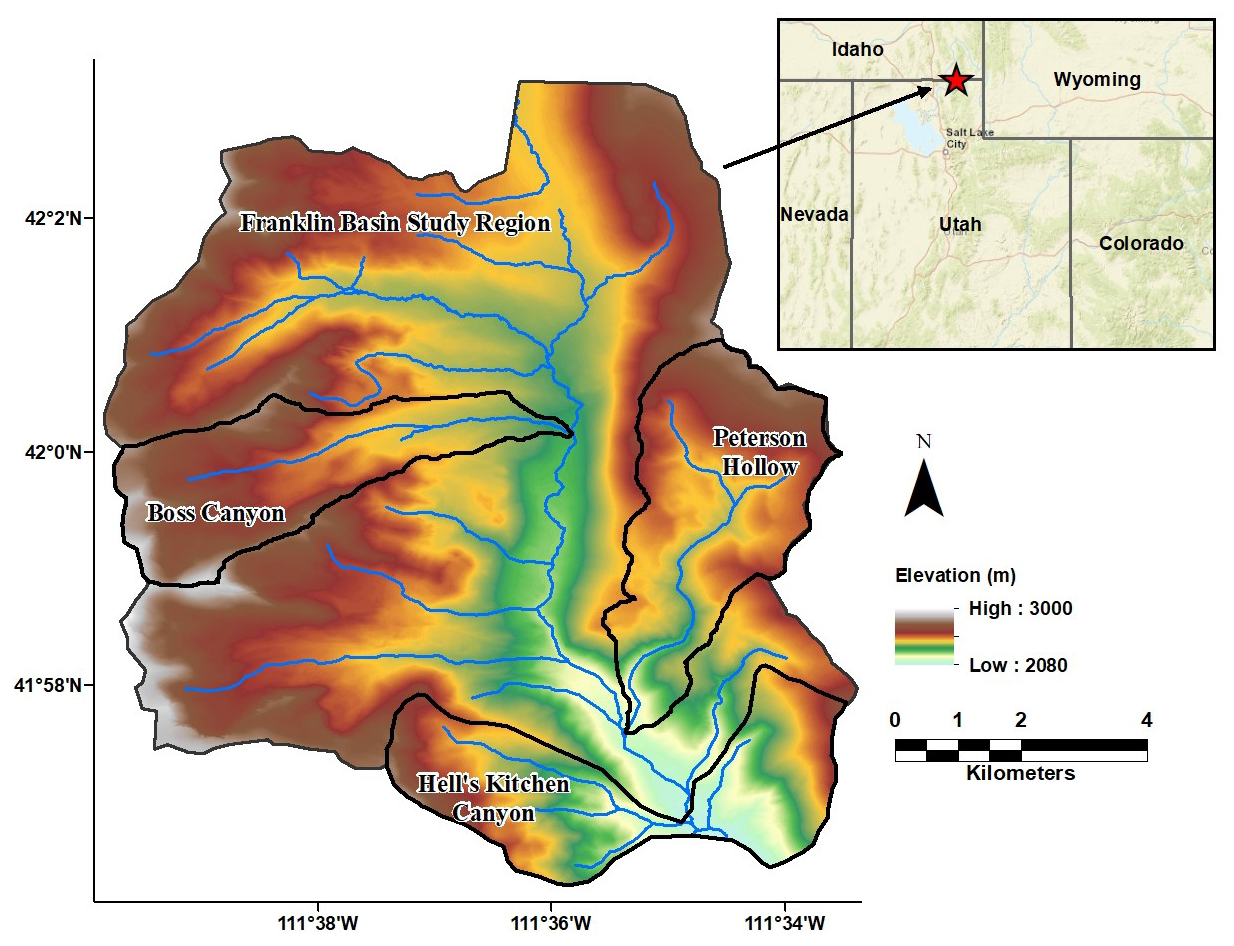
Figure 1Map of the Franklin Basin study area extents and elevation and the Boss Canyon, Peterson Hollow, and Hell's Kitchen Canyon subject subbasins in northern Utah and southern Idaho, US (inset map: ESRI).
Hell’s Kitchen Canyon is the southernmost subbasin in the study area and a popular recreation area throughout winter and summer. It has the lowest elevation of the three subbasin study areas (Table 1). Aspects are mainly northerly, southerly, and easterly facing, with an overall east-facing aspect. A small area to the east of the canyon watershed is included in the study area to include more westerly facing aspects during sampling and model training (Fig. 1). The Boss Canyon subbasin is located north of Hell’s Kitchen Canyon, with mainly northerly, southerly, and easterly facing aspects, and is an east-facing catchment. Peterson Hollow is a lower-elevation catchment within the region and a predominately southerly facing drainage. Vegetation variation is similar across all subbasins, with each area predominately consisting of forested evergreen, aspen, shrubland, and open-range areas. The furthest western areas of Boss Canyon and Franklin Basin contain high-elevation, steep, sparsely vegetated slopes on the eastern aspect of the Wasatch Range Ridge.
2.2 Data collection and preprocessing
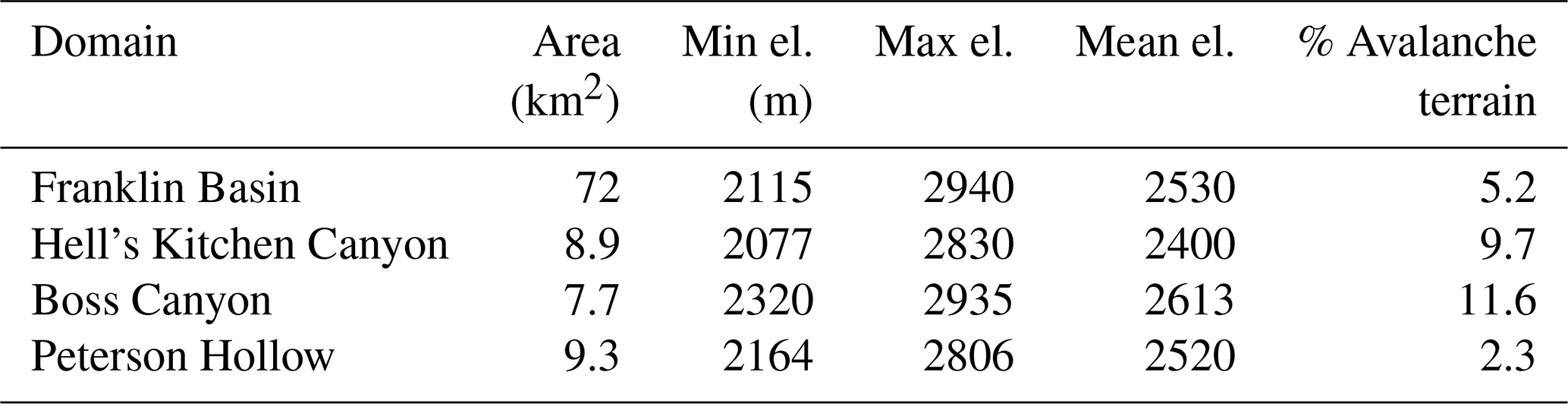
We collected snow-free lidar data of the Franklin Basin in the fall of 2020. The collection was performed with an Optech Galaxy T2000 and Prime on board a small aircraft at an altitude of 1300 m. An average flight density of 10.1 points per square meter was captured with a stated sensor absolute vertical accuracy of < 0.03–0.25 m RMSE from 150–6000 m above ground level. The data are referenced to the NAVD88 and NAD83 vertical and horizontal datums and reprojected from State Plane Utah North to the WGS 84/UTM Zone 12 coordinate system. We derived digital elevation model (DEM) and digital surface model (DSM) rasters from the obtained lidar and upscaled the resolution from its native resolution of 1.5 to a 50 m grid cell size with bi-linear interpolation to reduce computational demand (Table 2). The rasters for Hell's Kitchen Canyon were not upscaled, as this subbasin served as the field measurement boundary, requiring higher resolution to accurately guide samplers to precise sampling locations. The distribution of snow depth in the basin follows an approximately Gaussian distribution (Fig. 3), with a mean and standard deviation very close to a theoretical Gaussian distribution and a low Kolmogorov–Smirnov statistic (Eq. 10) of 0.06.
Table 2Metadata summary of snow depth and terrain datasets. In Franklin Basin, Boss Canyon, and Peterson Hollow, raster data were upscaled to improve computational efficiency. Hell's Kitchen Canyon raster data were maintained at 1.5 m for accurate locating of physical sampling locations.

We then extracted the physiographic parameters of slope, aspect, and canopy height (Fig. 2). We combine the slope and aspect grid values to calculate northness and eastness metrics with the equation
The values of northness and eastness both range from −1 to 1. In the northern hemisphere, a northness value of −1 corresponds to a steep, southerly facing slope, while a value of 1 indicates a steep, northerly facing slope. Similarly, an eastness value of −1 corresponds to a steep, west-facing slope, and a value of 1 corresponds to a steep, east-facing slope (Collados-Lara et al., 2017; Fassnacht et al., 2003). Both northness and eastness can be interpreted as proxies for exposure to solar radiation (Amatulli et al., 2018).
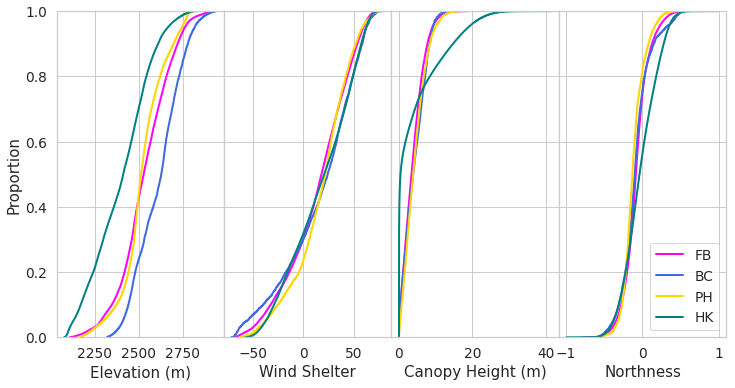
Figure 2Cumulative distributions of the physiographic features for each region domain. FB indicates Franklin Basin, BC denotes Boss Canyon, PH denotes Peterson Hollow, and HK denotes Hell's Kitchen.
We derive a wind shelter metric for the study domains according to the method of Winstral et al. (2002), quantifying the degree of shelter/exposure provided by upwind terrain. For each cell in the raster, a search distance of 100 m of the DEM in the northerly direction – the prevailing wind direction in the region – was applied (Western Regional Climate Center, 2022, 2022). As a final preprocessing step, we normalize the physiographic features from 0 to 1 with a min-max scaler to improve the stability of the model during learning.
To identify avalanche-prone terrain in the region, we inspect the average slope angle of each raster cell. Cells with a slope angle of 30° or greater are defined as having potential avalanche risk. For slopes below 30°, gravitational forces lack the strength to initiate a slide avalanche, so we consider these areas non-avalanche-prone (Maggioni and Gruber, 2003). The potential for avalanches to trigger on adjacent slopes or to progress to slopes below 30° exists; however, this was not included in our terrain assessment. From the classification, we create two data frames for the feature space – one includes all-terrain cells, and the other excludes cells marked as avalanche-prone – allowing us to compare them during model evaluation.
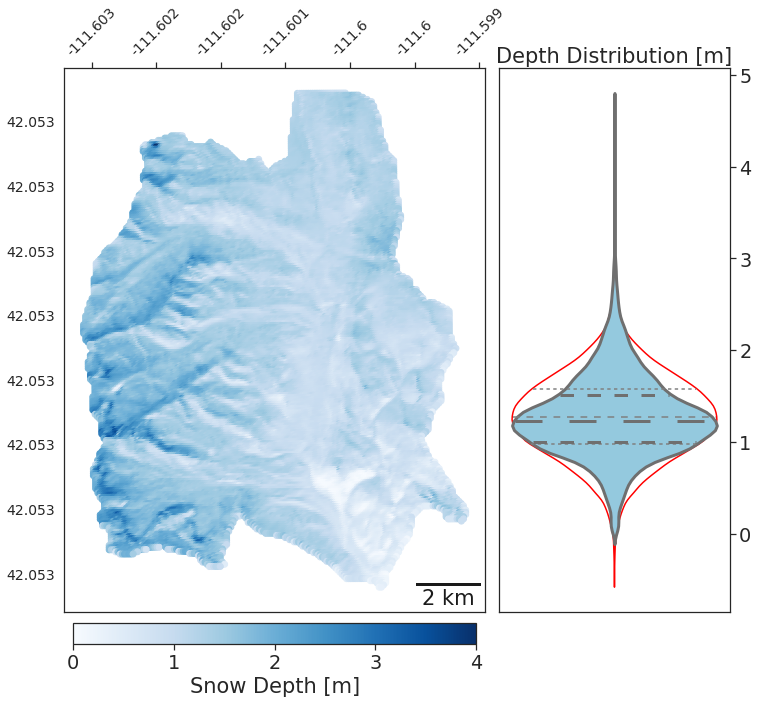
Figure 3Map and corresponding density distribution of the lidar-measured snow depth in Franklin Basin. The violin distribution of the snow depth is overlaid above a Gaussian distribution of 20 000 randomly generated samples to express the near-normality of the snow depth distribution. Quartiles of the snow depth are shown as bold hashed lines, and the light-gray hashed lines represent the Gaussian distribution quartiles.
On 28 March 2021, near the end of the accumulation season, the flight crew collected snow-on lidar data for Franklin Basin with the same instrumentation as the snow-free lidar. With the collected lidar, we developed a snow depth TIFF for the basin by raster subtracting the bare-earth DEM from the snow-on DEM. The result is a normally distributed snowpack across the basin, with a mean depth of 1.28 m and a standard deviation of 0.44 m. Due to flight pattern constraints, snow-on lidar was not captured for the Hell’s Kitchen area. The Franklin Basin, Boss Canyon, and Peterson Hollow raster resolutions were upscaled to 50 m to reduce the computation time. In comparison, the Hell's Kitchen Canyon bare-earth DEM was maintained at a 1.5 m resolution to provide detailed locations for the physical sampling.
2.3 Optimal measurement location identification
To optimally identify field sampling locations to produce snow depth estimates, we apply a multistep, Gaussian-based machine learning algorithm (Fig. 4). The framework builds on previous work, which found the algorithm successful in capturing snow depth variability within a basin with a small number of optimized sensors (Oroza et al., 2016). Our procedure involves using an unsupervised Gaussian mixture model (GMM) to identify sampling locations within Franklin Basin and its subbasins that best represent the region's physiographic composition based on snow-free topographic features (DEM elevation, northness, eastness, canopy height, and wind shelter). Unsupervised learning, like the GMM, requires no dependent variable input to identify these representative data points.
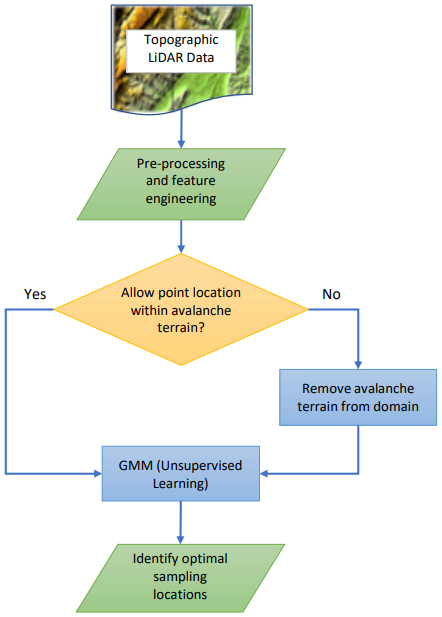
Figure 4Workflow of the optimal sample locating model. The model relies on the GMM to find the most physiographic representative points in a domain while considering avalanche-prone terrain.
The GMM is a probabilistic model that characterizes the feature space as a composition of several Gaussian distributed clusters, K, with mixing coefficients π such that
Each cluster is defined by a Gaussian density function (Eq. 3) of D dimensions, expected value, μ, and covariance, σ, where x represents the snow depth. The multivariate distribution is expressed as
The optimal μ and σ parameters for a given distribution can be found by taking the log of Eq. (3), differentiating, and equating it to zero. For multiple Gaussian distributions, optimal parameters are determined by maximizing the log-likelihood of all components over the entire feature space for a range of points, N. The log-likelihood of the GMM is defined as
We used the open-source Scikit-Learn Python library to execute the Gaussian mixture-based multistep optimization model (Pedregosa et al., 2011). To locate the optimal parameters for the dataset, the GMM employs the Expectation-Maximization (EM) algorithm (Dempster et al., 1977), given a specified number of clusters. The EM algorithm iteratively adjusts parameters for the mixture of components until it arrives at a maximization of the log-likelihood function, thus defining the most representative feature points within the dataset. To avoid convergence on local maxima, we run a grid search of randomized algorithm initializations with either 10 or 50 restarts to select the result that maximizes the log-marginal likelihood. We calculate with a spherical covariance kernel from a random seed of initial cluster origins and subsample 80 % of the domain for computational efficiency.
We defined the total number of clusters (sampling sites) as 10 to focus the study on sampling ability. A total of 10 sites allow field measurement collectors enough time to travel to all locations within a single day of sampling. To ensure that the limited number of sites does not adversely impact model performance, we test the sensitivity of the model to the number of training sites by executing multiple instances. For each of the Franklin Basin, Boss Canyon, and Peterson Hollow areas, we run the model initially with five clusters and increase the number of clusters with each iteration to 100. For each cluster center defined by the GMM, a ball-tree nearest-neighbor search method is applied to locate the cell location most closely represented by the features within the feature space. The output of the 10 GMM-identified optimal locations within the topographic feature domains of Franklin Basin, Boss Canyon, and Peterson Hollow is shown in Fig. 5. Within the Hell’s Kitchen Canyon subbasin, we performed a single model execution of 10 clusters to locate 10 optimal sampling sites for field measurement.
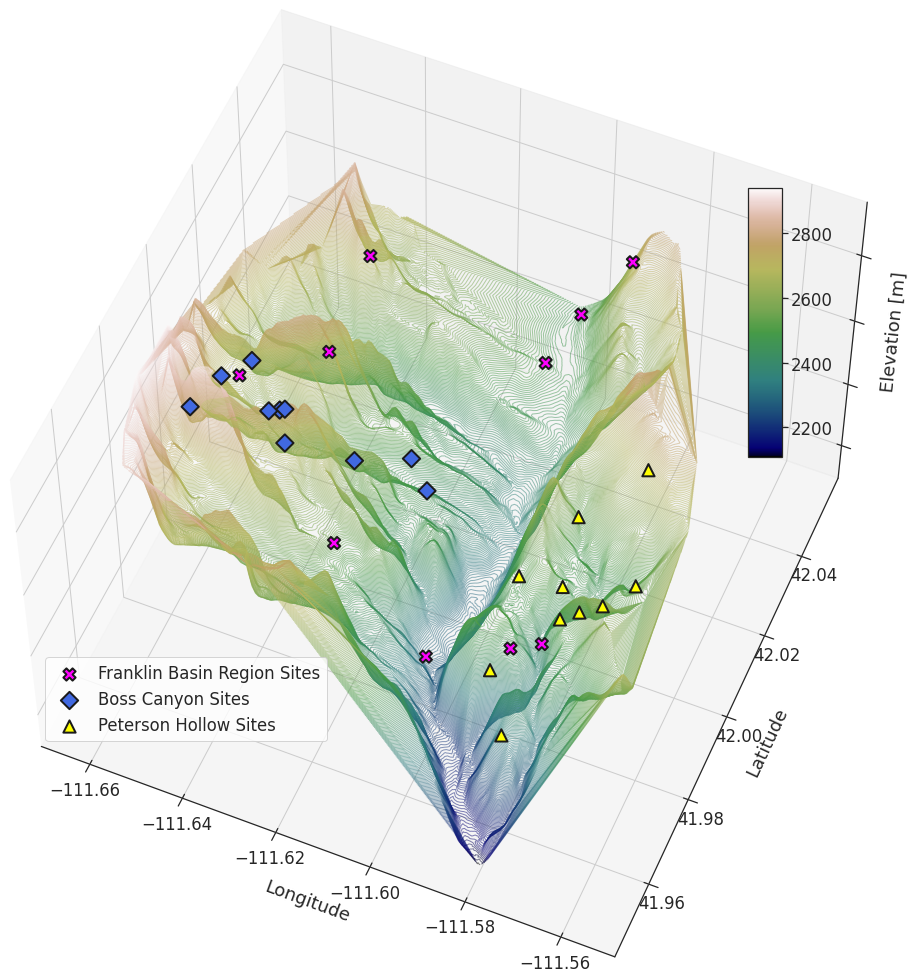
Figure 5A three-dimensional representation of the GMM output of the 10 most representative physiographic feature domain locations for Franklin Basin, Boss Canyon, and Peterson Hollow.
We run the GMM twice for each feature space: once including cells defined as avalanche-prone and once excluding them. In each scenario, we use the same GMM with the nearest-neighbor search method with an identical number of training sites. When avalanche terrain is excluded, the next most similar neighbor is selected instead if an avalanche-prone location is identified during the nearest-neighbor search.
2.4 Snow survey protocol
The 10 sampling locations identified by the GMM were the focus of a snow depth survey to retrieve in situ depth measurements. Simultaneously with the snow-on lidar flight on 28 March 2021, two researchers conducted a snow survey of the Hell's Kitchen Canyon study subbasin. The researchers reached the 10 locations at coordinates retrieved via a handheld Garmin inReach GPS device. The field team measured depth at each site throughout the subbasin via graduated snow depth probes. Each researcher took four measurements spaced evenly at the prescribed locations and recorded the average of the eight measurements. The first measurement was taken at approximately 09:40 am with an air temperature of 5.8 °C. Temperatures warmed throughout the day to 10.6 °C at the time and location of the final measurement. The weather was clear during sampling, and the nearby Dream Lift – KUTGARDE14 weather station (elev: 2220 m, 41.97° N, 111.54° W) measured the latest precipitation event, 5 days prior, with 0.46 cm of rain and 0.15 cm of snow. The most recent significant precipitation event measured at the station occurred 12 days prior, accumulating 2.59 cm of rain and 0.69 cm of snow. Temperatures over the past month at the station were consistently above 4.4 °C during the day while remaining below freezing at night, indicating melt periods in the snowpack with few accumulation periods.
2.5 Snow depth regression model
We model basin snow depth distribution throughout the study domain by applying a Gaussian process regression (GPR) model (Fig. 6). Gaussian processes are a method of supervised machine learning that resolves a probability distribution (Gaussian) of multiple multivariate functions with joint Gaussian distributions to fit a dataset (Williams and Rasmussen, 2006). The probabilistic and nonparametric nature of a GPR allows it to effectively capture underlying patterns even with minimal training data. A GPR model may be expressed as
where x represents a set of observations, m represents the mean function, defined as 𝔼[f(x)], and is a covariance function for all possible pairs of data points for a given set of hyperparameters.
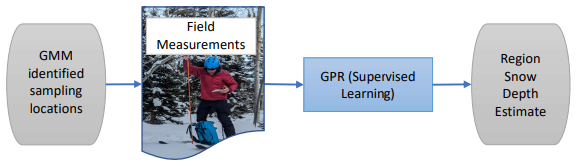
Figure 6Workflow of the snow estimation model. The model relies on the GPR, which collates static lidar features and point snow depth measurements to produce gridded snow depth estimates. In Hell's Kitchen Canyon, in situ-measured snow depths were used for the training data, while point observations of lidar-measured snow depth were used in the other domains.
The GPR predicts the dependent (target) variable snow depth for each point in the domain, given the independent variables (i.e., topographic parameters) and a prior covariance specified by a covariance function (kernel). GPR is categorized as a supervised machine learning regression technique, denoting that known values of the dependent variable are used during training to define a covariance-based relationship with the independent variables and to predict at locations where the target variable is unknown. The applied kernel determines the shape of the posterior distribution of the GPR. We use a radial basis function (RBF) (also referred to as a Gaussian or squared exponential covariance function), k, defined by Eq. (6), where xi, xj are two data points, d is the Euclidean distance between the two points, and l is a length-scale parameter.
The parameter l controls the rate at which the correlation between two points decreases concerning distance and influences the “smoothness” of the prediction function. To determine a value for l, we perform a grid search across a range of [0.01, 1] for every point, with the selected value being that which maximizes the log-marginal likelihood.
Within Hell’s Kitchen Canyon, field-measured snow depths from 10 locations are used as training data to estimate basin-wide snow depth based on sites outside of the estimation domain. For the other model scenarios, which lack snow survey data, lidar-derived snow depths at the GMM-identified locations are used to train the GPR model. In this approach, individual lidar point measurements serve as synthetic snow probe samples. To prevent information leakage between the training data and model validation, these point measurements are excluded from the validation dataset.
2.6 Model evaluation
We measure the performance of the model as the difference in the predicted snow depth from the lidar-derived snow depth throughout the basin. The standard mean bias error (MBE) (Eq. 7) and root mean squared error (RMSE) (Eq. 8) metrics are used to track and compare performance across the various model scenarios. MBE and RMSE are defined here as
where, for both formulas, n is the total number of points in the domain, is the estimated snow depth, and yi is the measured snow depth. Additionally, we report the Kling–Gupta efficiency (KGE) score of estimates (Eq. 9). KGE represents the goodness of fit between simulations to observations and incorporates the Pearson correlation coefficient (r), a term representing the variability of prediction error (α), and a bias term (β). KGE ranges from −inf to 1.0, with larger values indicating greater simulation efficiency and a KGE of 1.0 indicating perfect reproduction of observations (Gupta et al., 2009; Knoben et al., 2019).
For further analysis of the results, we define distribution similarity using the Kolmogorov–Smirnov (KS) test to define the KS statistic (D), defined by the equation
where Fn(x) is the empirical distribution function of the estimates, F(x) is the cumulative distribution function of the reference distribution, and supx denotes the supremum or the maximum value of the absolute difference across all values of x. The KS statistic measures the largest absolute difference between two distributions on a scale of 0 to 1, with a value of 0 indicating identical distributions (Conover, 1999).
To address the study objectives outlined in Sect. 1, we assess the model's performance across two distinct scenarios. First, we validate the model by estimating snow depth within a subbasin, utilizing only sampling sites from that basin. We compare the accuracy of snow depth estimates obtained from optimally located sites versus those from randomly selected sites. We also investigate how the number of sampling locations affects model accuracy by testing sparse measurements (e.g., 10 sites) against a more extensive dataset (e.g., 100 sites).
In the second scenario, we apply the validated model to estimate snow depth across the larger Franklin Basin, using sampling sites from selected subbasins (Objective ii). For this, we use either field-measured sample sites from Hell's Kitchen Canyon or point observations derived from lidar snow depth values as the training data for the GPR model. In both scenarios, we explore the impact of excluding avalanche-prone terrain from the sampling locations (Objective iii). Avalanche-prone cells are excluded during the GMM process and then reinstated for GPR snow depth estimation. The resulting snow depth estimates are then compared with those derived from the full-cell domain.
3.1 Algorithm validation
We validate the estimation capability of the GMM–GPR model within the study domain by processing snow depth estimates for the Boss Canyon and Peterson Hollow subbasins with lidar point observations sites in each catchment and comparing the scoring metrics (Table 3). In each tested scenario, optimally located sampling sites by the GMM resulted in reduced RMSE and improved MBE and KGE scores over randomly located sites. With 10 training sites optimally located by the GMM, the snow depth estimate results in RMSEs of 0.37 and 0.19 m for Boss Canyon and Peterson Hollow, compared to 0.43 and 0.33 m for random sites, respectively (Fig. 7). The resulting estimate is only slightly improved when increased to 100 optimally located sites. Comparing sampling sites at random locations throughout the watershed rather than algorithm-identified sites, the model RMSE for the 10 sites increases by 16 % and 74 %, with a greatly reduced bias for Boss Canyon and Peterson Hollow, respectively. Increasing the sampling to 100 randomly located sites slightly reduced the RMSE for Peterson Hollow compared to 10 random sites, with an improvement in MBE, while the error was exacerbated for Boss Canyon. The increased random sampling rate still results in greater error than just using the 10 optimized locations. For each scenario, modeled snow depth was slightly underestimated. The full sensitivity analysis may be found in Fig. S1 of the Supplement.
Table 3Model scenario and accuracy metrics for snow depth estimates of the Boss Canyon and Peterson Hollow subbasins and the full Franklin Basin region. Each scenario was executed for randomly selected and optimal locations (GMM) within the respective sampling subbasin, with 10 or 100 locations, and with and without avalanche-prone (Avy.) terrain. Model-identified training locations show improved estimation performance over randomly selected sites. Increasing the number of optimized sites provides a slight improvement in accuracy in most scenarios.
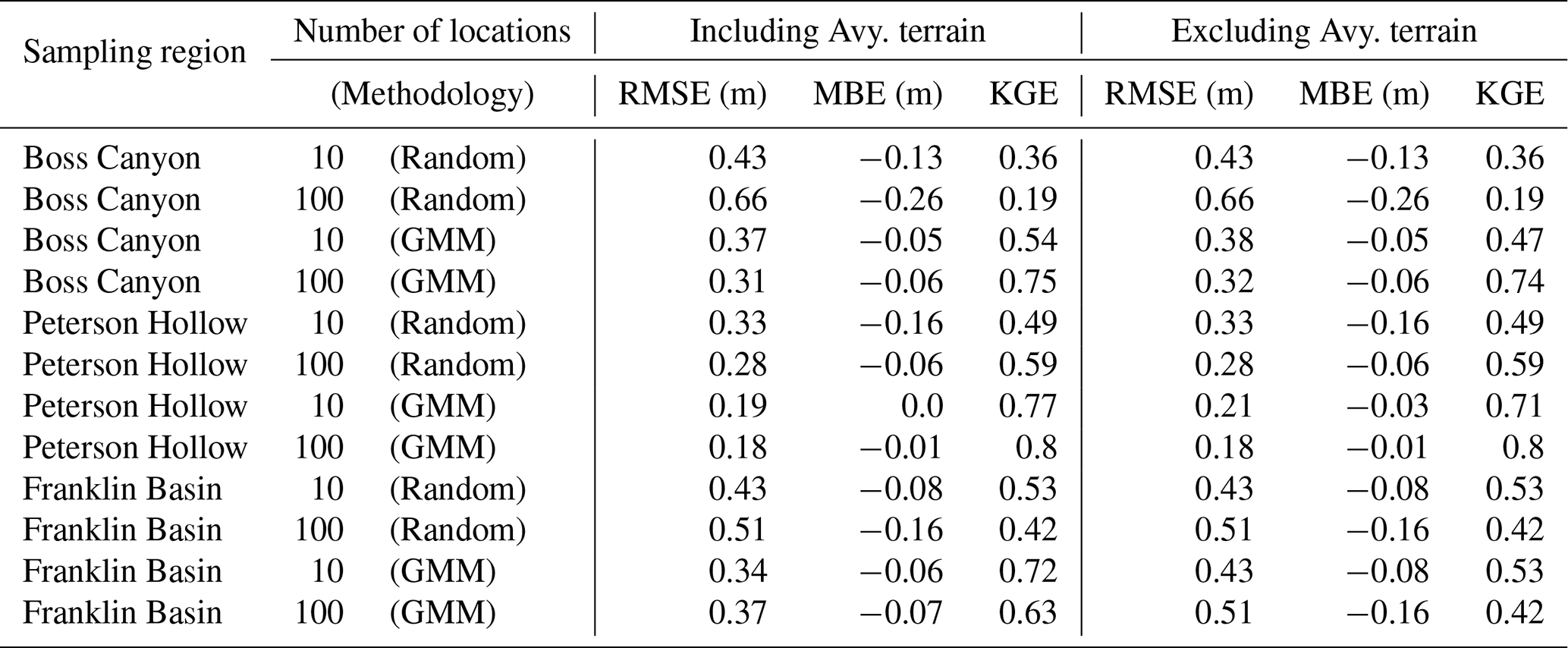
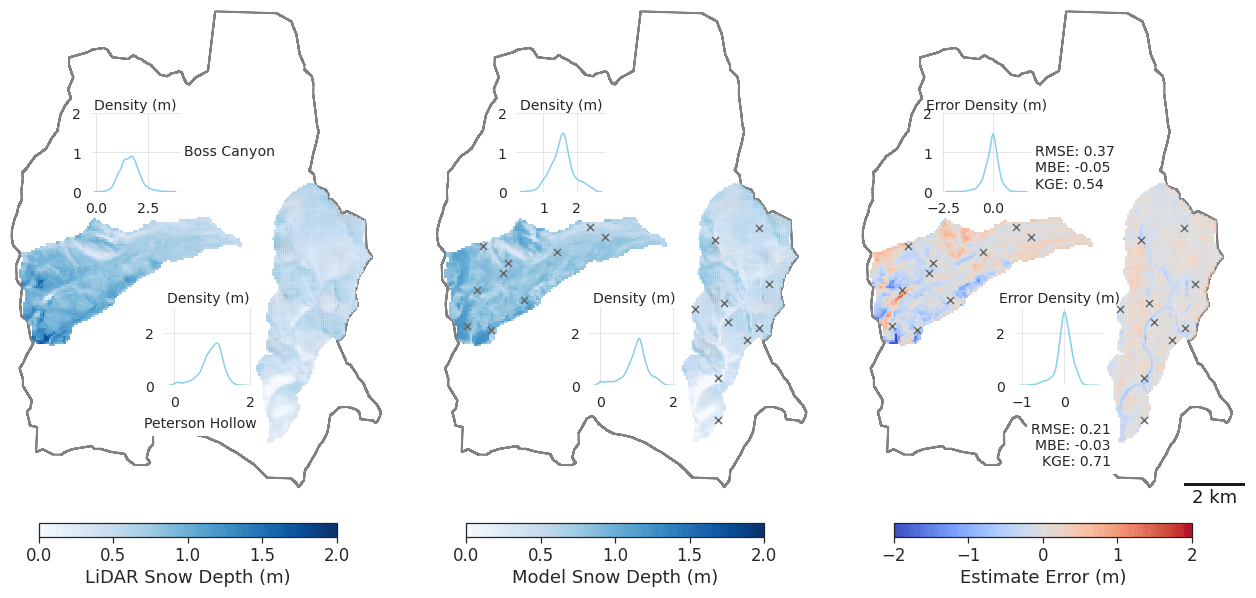
Figure 7Subbasin lidar snow depth, estimated snow depth, and estimation error for Boss Canyon and Peterson Hollow for 10 model-identified optimal sampling locations (×) and associated accuracy metrics.
3.2 Impact of avalanche terrain removal
The exclusion of avalanche-prone terrain had minimal influence on the resulting model estimation. When the high-risk cells are excluded from the potential sampling domain for Boss Canyon, the RMSE of the subbasin snow depth estimate for the 10 training locations increases by 2.7 %. The MBE remains unaffected, and the KGE is slightly reduced from 0.54 to 0.47. For the 10 sites within Peterson Hollow, when accounting for avalanche terrain, the subbasin estimate RMSE expresses an increase of 11 % and a slight increase in MBE and reduction of KGE. The potential for optimal sampling sites being identified in avalanche-prone terrain increases as the number of sites increases, though the model remains robust when increasing the sampling site total and excluding the terrain. We find no significant change in the model score when the training set is increased to 100 sites outside of high-risk terrain. The Boss Canyon watershed estimate RMSE improves by 3.2 %, and KGE decreases by 1.3 %. In Peterson Hollow, the accuracy metrics do not change with the increase in the number of sites considered.
3.3 Estimation beyond the sampling region
Expanding the estimation domain beyond the smaller subbasin sampling spatial bounds results in effective snow depth modeling at the greater basin scale. We compare the results of the basin estimate for the various scenarios of 10 sites in a subbasin excluding avalanche terrain (Fig. 8). For the Franklin Basin sampling instance, the RMSE of the basin estimate exhibits an RMSE of 0.34 m, an MBE of −0.06 m, and a KGE of 0.72. All subbasin sampling domain estimations result in RMSEs similar to that of the basin sampled estimate (within 28 %), with Boss Canyon providing the lowest RMSE (0.37 m) of the three subbasins and Hell's Kitchen Canyon providing the largest (0.45 m). Hell's Kitchen Canyon also provides the lowest KGE (0.39), while Peterson Hollow maintains the highest (0.59). The absolute value of MBE is within 0.22 m for each estimate, with Boss Canyon and Hell's Kitchen Canyon slightly overestimating the basin's snow depth, while Peterson Hollow underestimates on average.
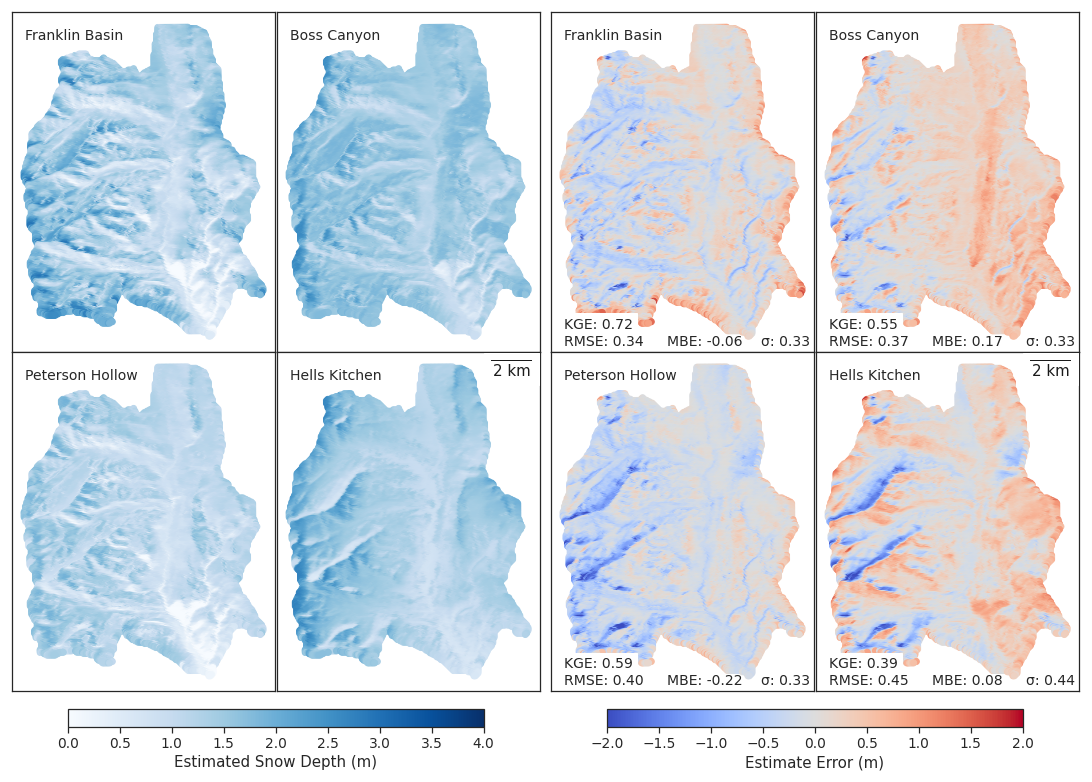
Figure 8Basin-scale snow depth estimates (left), and snow depth estimate errors (right) with associated accuracy metrics derived from the sampling domains of Franklin Basin (top left), Boss Canyon (top right), Peterson Hollow (bottom left), and Hell's Kitchen Canyon (bottom right). The estimates were derived with 10 GMM-identified, optimal sampling locations outside of avalanche-prone terrain to train the GPR model.
While the Hell's Kitchen Canyon derived estimate exhibits slightly greater RMSE than the Boss Canyon and Peterson Hollow estimates, the overall snow depth distribution is more similar to the true distribution (Fig. 9). The Hell's Kitchen Canyon estimated snow depth exhibits a DHK of 0.13, and only the Franklin Basin derived estimate is more similar to the true distribution, with DFB=0.10. The overestimation of the Boss Canyon estimate can be observed in the distribution plot and with the greatest KS statistic of DBC=0.28. For all subbasin estimates, errors increase with elevation (Fig. 10).
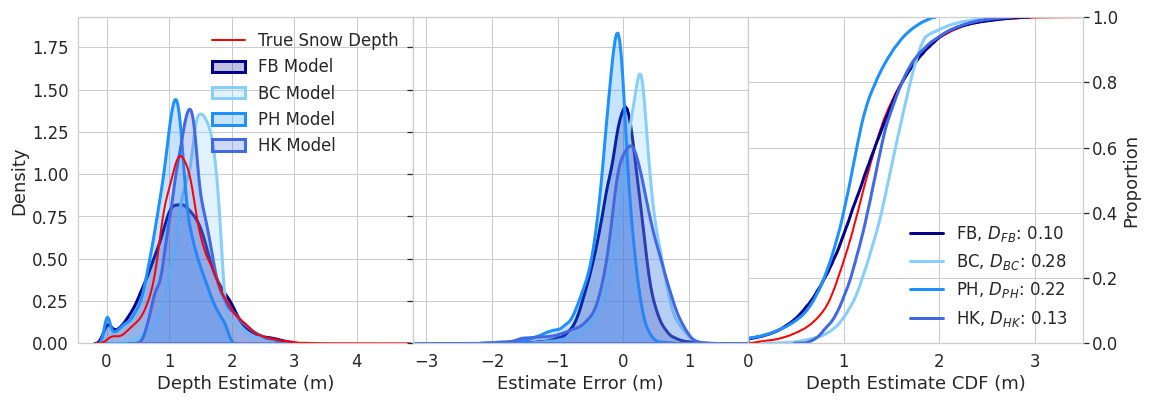
Figure 9Distribution of basin-scale snow depth estimates for the four sampling domains, where FB indicates Franklin Basin, BC denotes Boss Canyon, PH denotes Peterson Hollow, and HK denotes Hell's Kitchen Canyon. D is the Kolmogorov–Smirnov statistic indicating distribution similarity between the estimate and true snow depth.
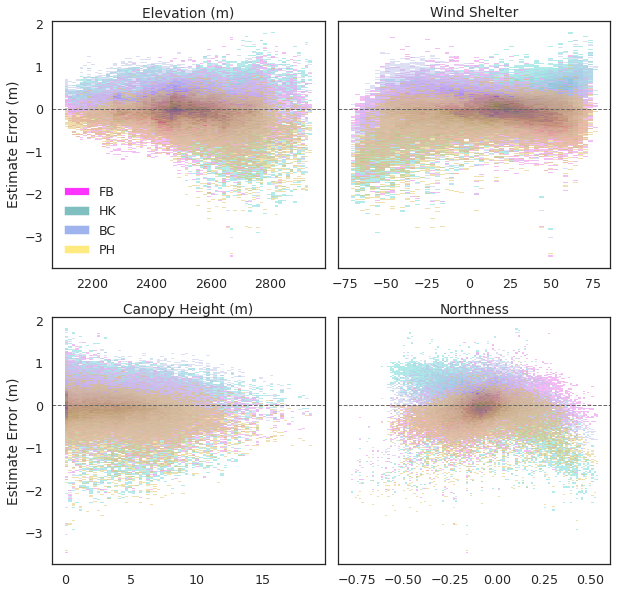
Figure 10Distribution of basin-scale snow depth estimate errors for the individual physiographic features. Estimate variance is greater, particularly at higher elevations and at the extremes of the wind shelter spectrum. The Hell's Kitchen Canyon estimate exhibits the largest variance across all variables.
When comparing the results of the estimates with avalanche-prone terrain excluded to estimates that included the terrain, we observe minimal performance loss in basin-scale estimation. The result of excluding avalanche terrain in the Franklin Basin sampling domain does not affect the estimation error, as the 10 most characteristic sites are located outside of avalanche terrain. Excluding the terrain within Boss Canyon results in a 2.5 % increase in RMSE and an improvement of MBE from 0.17 to 0.15 m relative to basin estimates. Meanwhile, Peterson Hollow estimates exhibit an increase of 7.5 % in RMSE and a 12 % drop in MBE. No instance of included avalanche terrain was executed in the Hell's Kitchen Canyon analysis due to the constraint of having only one snow survey, which did not allow for sampling avalanche-prone areas.
4.1 Performance across subbasins
For each modeled scenario, the model consistently produced accurate snow depth estimates based on a small number of training locations and with better accuracy than random sampling (Table 3). Both the Boss Canyon and Peterson Hollow scenarios showed small decreases in accuracy when the estimation was expanded to the full basin, though they maintained similar MBEs and distributions. Peterson Hollow exhibited a greater drop in accuracy than Boss Canyon when estimating beyond its border due to its more homogenous feature distribution. Despite the decreased performance, the larger region-scale estimate from the GMM-identified Peterson Hollow sites exceeded the accuracy of random sites throughout the basin. In Hell's Kitchen Canyon, a subbasin outside of the Franklin Basin domain, the similarity of the basin-scale estimate distribution exemplifies how it can adequately estimate snowpack in the basin, though with slightly worse scoring metrics than the other subbasins. This indicates that a smaller sampling catchment with optimized sampling sites can be accurately applied to model a larger or similar basin without sacrificing performance, though perhaps up to a limit.
4.2 Sampling constraints and practical considerations
Small improvements in model performance were observed as we increased the number of sampling locations beyond 10 sites and when considering a larger spatial sampling domain. However, increasing the number or spatial range of sites makes it infeasible for a group of samplers to collect snow depth samples in a single day. The ability to collect data quickly is critical to accurately representing the snowpack before changes occur, such as melting or new accumulation. Additionally, access to sampling locations and the availability of citizen-scientist-collected data may be limited to certain areas. For example, Hell's Kitchen Canyon is a popular outdoor recreation area with nearby parking and trail access. It is more likely to see traffic, which may result in more data collection than in a more remote area. Under different conditions, a sampling team may reach more than 10 sites in a day, such as with multiple teams taking samples simultaneously, or there may be many snow probe data points at a higher density in a larger region. Conversely, sampling may be more challenging in a more remote or complex environment, and the quality of sampling may be worse.
While 10 sites were selected as the focus of this study, we did not aim to determine an optimal number of locations for a snow survey. During model validation, we observed variation in performance from incremental increases in the number of training sites (e.g., increasing from 10 to 11 sites). However, the overall trend across all basins was consistent: increasing the number of points did not significantly improve model performance over a smaller sample, such as 10 (Fig. S1). We hypothesize that an optimal sample number is dependent on factors such as basin size, regional characteristics, and terrain complexity. Therefore, determining the optimal or projected number of physically collected sampling points becomes a complex calculation of sampling area, group size, region traffic, and community engagement with data collection. Future work shall identify the lower bounds of sampling sites and region size that may still produce representative results. For the subbasins in our study and a group of two samplers, approximately 10 sites were the most they could safely measure in 1 day without mechanized travel, and we consider the 10-site simulations relevant and realistic for similar environments and scales. Additionally, future work could explore a single-site (e.g., SNOTEL-based) framework to assess temporally continuous model performance. However, due to a lack of validation data, this was beyond the scope of our study. We anticipate that using only one or very few sampling sites would lead to a highly biased and overfitted model, as the GPR would struggle to capture the underlying spatial relationships.
It should be noted that the specified accuracy range of the lidar sensor (< 0.03–0.25 m) may be significant, considering the depth of snowpack in the region, and warrants further examination. For the Hell's Kitchen Canyon simulation, which relies on field measurements, errors in lidar data or in the depth probe measurements may lead to biases in the overall snow depth estimate. Although the impact of uncertainty on the study's results is unclear, the synthetic sampling method in the other domains mitigates additional error by directly comparing lidar measurements to lidar measurements. Further research should involve validating the model with diverse lidar sources and additional ground-truth datasets to quantify and characterize the error.
4.3 Influence of avalanche-prone terrain
The model showed low sensitivity to the consideration of avalanche-prone terrain. In all scenarios, excluding high-risk terrain led to minimal or negligible increases in estimation RMSE for the tested regions. Thus, snow samplers' safety is protected without sacrificing significant estimate accuracy, as they do not need to physically sample in higher-risk terrain. While the absence of terrain does not greatly impact the average basin estimate, it does have a larger effect on the estimation bias observed. The Boss Canyon estimate suffers from more underestimation of snow depth, likely due to the underrepresentation of higher elevations, which are largely associated with avalanche-prone slopes within the canyon. Additionally, only 5 % of the cells within Franklin Basin and 10 % within Hell's Kitchen Canyon consist of terrain defined as avalanche-prone. This allows for an adequate sampling domain outside of avalanche risk, with a broad enough range of features to represent the region in safe-to-sample locations.
While a slope angle of 30° is a commonly referenced threshold for avalanches, accurately determining avalanche terrain is often more complex. Avalanches may run out to flatter areas beyond the risk terrain analyzed in this study or may propagate horizontally to areas of slope angles below the threshold. In steeper, more complex terrain, the area unavailable for safe sampling may be much larger, and the estimation performance observed in Franklin Basin may not be exhibited in other regions. Future work will aim to apply the model to additional regions of steep terrain to determine the potential limits of domain exclusion from avalanche terrain.
4.4 Sampling domain similarity and model performance
A key assumption of the methodology is that there is enough characteristic variety in the sampling domain to represent the variability in the feature space of the estimation region. We can observe this dependency on sampling and estimation domain similarity by comparing the physiographic features of the various domains (Fig. 2). Hell's Kitchen Canyon's canopy height distribution appears very dissimilar to the other canopy distributions. This is due to the spatial resolution difference between Hell's Kitchen Canyon and the other domains. Hell's Kitchen Canyon maintains a higher resolution that is capable of capturing the smaller variations in canopy height, whereas this detail is averaged out during the upscaling process of the other regions. The increased variance of values likely contributes to the Hell's Kitchen Canyon model resulting in poorer performance than the other models. However, we posit that with uniform resolution, the feature space would present more analogous to Franklin Basin's and thus improve results.
By comparing the individual topographic features to estimate error, we observe the largest variance of error correlated with higher elevations and at the extremes of the wind shelter metric (i.e., fully exposed or sheltered terrain) (Fig. 10). In a small, snow-fed catchment (< 1 km2), wind redistribution of snow may be the most important factor for snowpack accumulation and persistence, with the best predictor of single-point snow depth being its elevation relative to the neighboring terrain at a 40 m radius (Anderton et al., 2004). In practice, however, obtaining or generating accurate wind scales for snow depth estimation at the basin scale is challenging and requires the downscaling of computational fluid dynamic models or high-resolution numerical weather prediction models (Reynolds et al., 2021). Another approach is to classify persistent locations of wind-drifted snow from remote sensing imagery for feature development, though this requires historical analysis and the addition of multiple data sources. Overall, a more detailed investigation of the local wind dynamics in a sampling region beyond the simplified wind shelter metric applied in this study may be considered to improve model performance.
While redistribution factors such as wind play a major role in snow depth distribution, the elevation relationship is also central. In alpine environments, snow depth tends to increase with elevation up to a point correlating with prominent rock coverage and then decreases beyond. The decrease in depth at high elevation is likely due to redistribution and preferential deposition factors, such as wind transport, avalanching, and sloughing from steeper to shallower slopes (Grünewald et al., 2014). Additionally, orographic precipitation dynamics can result in varying elevation precipitation patterns (Roe and Baker, 2006). We can observe the model elevation dependence, particularly in the Boss Canyon results, which contain the highest percentage of high-elevation cells among all subbasins. This leads to the most accurate depth estimates at higher elevations and ridgelines in the large-scale analysis. In contrast, the lower subbasins of Peterson Hollow and Hell's Kitchen Canyon show weaker performance in estimating these areas.
More normally distributed in feature space than the other regions, Peterson Hollow lacks the topographic diversity to accurately estimate snow depth at the highest elevations and particularly on northerly aspects. The lack of high elevations in Peterson Hollow likely causes it to fail relative to the other subbasins in representing the high-elevation transport dynamics of the larger Franklin Basin, resulting in high-elevation underestimation. Alternatively, Boss Canyon encompasses a broader feature range, more similar to the greater basin, and results in a more accurate estimate. Thus, selecting a diverse and representative sampling area is advantageous when modeling beyond the spatial bounds of the sampling area.
The distinction in basin elevation distribution between the regions is identifiable. Hell's Kitchen Canyon, which sits at a lower elevation than the overall Franklin Basin, exhibited greater error at high elevations and along mountain ridgelines (Fig. 8). In contrast, Boss Canyon, with a higher average elevation, showed greater snow depth estimation errors at lower elevations. These results suggest that elevation plays a crucial role in model accuracy, and selecting a representative sampling domain is key to minimizing estimation bias.
4.5 Implications for model transferability and future work
To improve model transferability, incorporating additional features such as radiative forcing, land cover, and atmospheric properties may help compensate for the limitations of the physiographic feature space. In this study, we constrained the feature space to maintain efficient domain preprocessing and execution using a single lidar dataset. However, expanding the feature space could enhance model performance, particularly in regions with more complex snowpack dynamics. Future studies should explore the benefits of integrating multisource datasets to refine snow depth estimations across diverse topographic environments.
While this methodology was shown to be effective in the study region of northern Utah and southern Idaho, application in other regions is necessary to evaluate performance across various topographic environments and snow climates. The snow distribution of Franklin Basin at the time of sampling presented as near-Gaussian (Fig. 3). The expectation of a Gaussian distributed target variable is a key assumption of a GPR model. While snow depth often appears as Gaussian in subalpine and non-ephemeral regions, non-Gaussian distributions are observed in more complex or ephemeral environments (He et al., 2019; Ohara et al., 2024). Application of the model in more diverse snow environments, including basins with greater exposure to wind-swept terrain above the treeline, and basins with snow-free areas is needed to understand transferability to regions less likely to meet the Gaussian assumption. Additionally, this study is performed for a single date towards the end of the snow season. More sampling dates and periods throughout the snow season, especially after snow accumulation events, should be investigated to determine the temporal strength and sensitivity of the model.
The development of low-cost, near-real-time snow estimation is critical for water resource monitoring, particularly in remote, unmonitored regions. With this study, we introduce a methodology leveraging physiographic features derived from one-time-captured snow-off lidar and a small number of in situ sampling points to generate region-scale snow depth estimates with low cost and high temporal efficiency. A two-step machine learning workflow is applied. First, a Gaussian mixture model is used to locate optimal sampling locations based on feature representation. These locations are then sampled for point snow depth values and used to train a Gaussian process regression algorithm to estimate broad-scale snow depths. We find that with few (i.e., 10) optimized sampling points, the model is effective at estimation both at the subbasin and greater basin scales. The solution proves robust for model scenarios encompassing both the sampling subbasin (Boss Canyon and Peterson Hollow) and for a sampling subbasin (Hell's Kitchen Canyon) outside of the estimate bounds. With the goal of lowering the avalanche risk of individuals sampling snow depths in the field, we test the sensitivity of the model to the exclusion of avalanche-prone terrain from the sampling domain. When high-risk terrain is removed, we observe that the model produces snow depth estimates with minimal performance loss. Results demonstrate that a relatively small number of optimal sampling locations can effectively model snow depth across a broader region, reducing the need for extensive sampling campaigns. This approach provides a use case for accurate snow modeling via application of a low-cost snow probe measurement while prioritizing safety and systematically reducing personnel danger in the field.
The data that support the findings of this study are openly available from the repository at https://doi.org/10.4211/hs.34ce22e4df10463cb053bb63d19d6672 (Liljestrand et al., 2023).
The supplement related to this article is available online at https://doi.org/10.5194/tc-19-3123-2025-supplement.
DL: conceptualization, data curation and field sampling, formal analysis, methodology, software and code development, validation, visualization, writing – original draft, writing – review and editing. RJ: writing – review and editing. BN: funding acquisition, project administration, supervision, writing – review and editing. PS: field sampling, writing – review and editing. EC: code development.
The contact author has declared that none of the authors has any competing interests.
Publisher’s note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors.
This work was made possible through funding provided by the United States Geological Survey, the Logan River Observatory (USU), and the Cooperative Institute for Research to Operations in Hydrology (CIROH). The authors would like to acknowledge the contribution of the following individuals and organizations: Carlos Oroza PhD (UofU), Michael Jarzin Jr. (UofU), data hosting and mobile collection provided by Community Snow Observations (http://www.communitysnowobs.org, last access: 6 August 2025), lidar flown by Aero-Graphics Inc., SLC, UT, and field safety training and planning provided by the American Avalanche Institute, Jackson, WY.
This research has been supported by the US Geological Survey (USGS 104b Projects (grant no. G16AP00086)) and the National Oceanic and Atmospheric Administration (NOAA Cooperative Agreement with The University of Alabama and CIROH (grant no. NA22NWS4320003)).
This paper was edited by Nora Helbig and reviewed by three anonymous referees.
Amatulli, G., Domisch, S., Tuanmu, M.-N., Parmentier, B., Ranipeta, A., Malczyk, J., and Jetz, W.: A suite of global, cross-scale topographic variables for environmental and biodiversity modeling, Scientific Data, 5, 1–15, 2018. a
Anderton, S., White, S., and Alvera, B.: Evaluation of spatial variability in snow water equivalent for a high mountain catchment, Hydrol. Process., 18, 435–453, 2004. a
Bales, R. C., Molotch, N. P., Painter, T. H., Dettinger, M. D., Rice, R., and Dozier, J.: Mountain hydrology of the western United States, Water Resour. Res., 42, W08432, https://doi.org/10.1029/2005WR004387, 2006. a
Barnett, T. P., Adam, J. C., and Lettenmaier, D. P.: Potential impacts of a warming climate on water availability in snow-dominated regions, Nature, 438, 303–309, 2005. a
Barrett, A.: National Operational Hydrologic Remote Sensing Center SNOw Data Assimiliation System (SNODAS) products at NSIDC, National Snow and Ice Data Center, Boulder, Special Report 11, 19, 2003. a
CAIC: Colorado Avalanche Information Center Statistics and Reporting, https://avalanche.state.co.us/accidents/statistics-and-reporting (last access: 28 December 2022), 2022. a
Clark, M. P., Hendrikx, J., Slater, A. G., Kavetski, D., Anderson, B., Cullen, N. J., Kerr, T., Örn Hreinsson, E., and Woods, R. A.: Representing spatial variability of snow water equivalent in hydrologic and land-surface models: A review, Water Resour. Res., 47, W07539, https://doi.org/10.1029/2011WR010745, 2011. a
Clow, D. W., Nanus, L., Verdin, K. L., and Schmidt, J.: Evaluation of SNODAS snow depth and snow water equivalent estimates for the Colorado Rocky Mountains, USA, Hydrol. Process., 26, 2583–2591, 2012. a, b
Collados-Lara, A.-J., Pardo-Igúzquiza, E., and Pulido-Velazquez, D.: Spatiotemporal estimation of snow depth using point data from snow stakes, digital terrain models, and satellite data, Hydrol. Process., 31, 1966–1982, 2017. a
Collados-Lara, A.-J., Pardo-Igúzquiza, E., and Pulido-Velazquez, D.: Optimal design of snow stake networks to estimate snow depth in an alpine mountain range, Hydrol. Process., 34, 82–95, 2020. a
Conover, W. J.: Practical nonparametric statistics, vol. 350, John Wiley & Sons, ISBN 978-0-471-16068-7, 1999. a
Crumley, R. L., Hill, D. F., Wikstrom Jones, K., Wolken, G. J., Arendt, A. A., Aragon, C. M., Cosgrove, C., and Community Snow Observations Participants: Assimilation of citizen science data in snowpack modeling using a new snow data set: Community Snow Observations, Hydrol. Earth Syst. Sci., 25, 4651–4680, https://doi.org/10.5194/hess-25-4651-2021, 2021. a
Deems, J. S., Painter, T. H., and Finnegan, D. C.: Lidar measurement of snow depth: a review, J. Glaciol., 59, 467–479, 2013. a
Dempster, A. P., Laird, N. M., and Rubin, D. B.: Maximum likelihood from incomplete data via the EM algorithm, J. R. Stat. Soc. B, 39, 1–22, 1977. a
Dover, J. H.: Geologic Map of the Logan 30'× 60'Quadrangle, Cache and Rich Counties Utah, and Lincoln and Uinta Counties, Wyoming, US Geological Survey, https://doi.org/10.3133/i2210, 1995. a
Fassnacht, S., Dressler, K., and Bales, R.: Snow water equivalent interpolation for the Colorado River Basin from snow telemetry (SNOTEL) data, Water Resour. Res., 39, 1208, https://doi.org/10.1029/2002WR001512, 2003. a
Galeati, G., Rossi, G., Pini, G., and Zilli, G.: Optimization of a snow network by multivariate statistical analysis, Hydrolog. Sci. J., 31, 93–108, 1986. a
Grünewald, T., Bühler, Y., and Lehning, M.: Elevation dependency of mountain snow depth, The Cryosphere, 8, 2381–2394, https://doi.org/10.5194/tc-8-2381-2014, 2014. a
Gupta, H. V., Kling, H., Yilmaz, K. K., and Martinez, G. F.: Decomposition of the mean squared error and NSE performance criteria: Implications for improving hydrological modelling, J. Hydrol., 377, 80–91, 2009. a
Harder, P., Schirmer, M., Pomeroy, J., and Helgason, W.: Accuracy of snow depth estimation in mountain and prairie environments by an unmanned aerial vehicle, The Cryosphere, 10, 2559–2571, https://doi.org/10.5194/tc-10-2559-2016, 2016. a
He, S., Ohara, N., and Miller, S. N.: Understanding subgrid variability of snow depth at 1-km scale using Lidar measurements, Hydrol. Process., 33, 1525–1537, 2019. a, b
Herbert, J. N., Raleigh, M. S., and Small, E. E.: Reanalyzing the spatial representativeness of snow depth at automated monitoring stations using airborne lidar data, The Cryosphere, 18, 3495–3512, https://doi.org/10.5194/tc-18-3495-2024, 2024. a
Jonas, T., Marty, C., and Magnusson, J.: Estimating the snow water equivalent from snow depth measurements in the Swiss Alps, J. Hydrol., 378, 161–167, 2009. a
Kerkez, B., Glaser, S. D., Bales, R. C., and Meadows, M. W.: Design and performance of a wireless sensor network for catchment-scale snow and soil moisture measurements, Water Resour. Res., 48, W09515, https://doi.org/10.1029/2011WR011214, 2012. a
Knoben, W. J. M., Freer, J. E., and Woods, R. A.: Technical note: Inherent benchmark or not? Comparing Nash–Sutcliffe and Kling–Gupta efficiency scores, Hydrol. Earth Syst. Sci., 23, 4323–4331, https://doi.org/10.5194/hess-23-4323-2019, 2019. a
Liljestrand, D., Neilson, B., and Oroza, C.: Franklin Basin, UT, USA Snow-On LiDAR, HydroShare [data set], https://doi.org/10.4211/hs.34ce22e4df10463cb053bb63d19d6672, 2023. a
López-Moreno, J. I., Fassnacht, S. R., Beguería, S., and Latron, J. B. P.: Variability of snow depth at the plot scale: implications for mean depth estimation and sampling strategies, The Cryosphere, 5, 617–629, https://doi.org/10.5194/tc-5-617-2011, 2011. a
Lundquist, J. D., Dettinger, M. D., and Cayan, D. R.: Snow-fed streamflow timing at different basin scales: Case study of the Tuolumne River above Hetch Hetchy, Yosemite, California, Water Resour. Res. 41, W07005, https://doi.org/10.1029/2004WR003933, 2005. a
Maggioni, M. and Gruber, U.: The influence of topographic parameters on avalanche release dimension and frequency, Cold Reg. Sci. Technol., 37, 407–419, 2003. a
Meromy, L., Molotch, N. P., Link, T. E., Fassnacht, S. R., and Rice, R.: Subgrid variability of snow water equivalent at operational snow stations in the western USA, Hydrol. Process., 27, 2383–2400, 2013. a
Molotch, N. P. and Bales, R. C.: Scaling snow observations from the point to the grid element: Implications for observation network design, Water Resour. Res., 41, W11421, https://doi.org/10.1029/2005WR004229, 2005. a
Mote, P. W., Hamlet, A. F., Clark, M. P., and Lettenmaier, D. P.: Declining mountain snowpack in western North America, B. Am. Meteorol. Soc., 86, 39–50, 2005. a
Mote, P. W., Li, S., Lettenmaier, D. P., Xiao, M., and Engel, R.: Dramatic declines in snowpack in the western US, Npj Climate and Atmospheric Science, 1, 2, https://doi.org/10.1038/s41612-018-0012-1, 2018. a
Neilson, B. T., Strong, P., and Horsburgh, J. S.: State of the Logan River Watershed. Utah Water Research Laboratory, Utah State University, Logan, Utah, USA, https://uwrl.usu.edu/files/pdf/2020-21-lro-annual-report.pdf (last access: 11 August 2025), 2021. a
NRCS: SNOwpack TELemetry Network (SNOTEL), https://data.nal.usda.gov/dataset/snowpack-telemetry-network-snotel (last access: 28 June 2022), 2022. a
Ohara, N., Parsekian, A. D., Jones, B. M., Rangel, R. C., Hinkel, K. M., and Perdigão, R. A. P.: Characterization of non-Gaussianity in the snow distributions of various landscapes, The Cryosphere, 18, 5139–5152, https://doi.org/10.5194/tc-18-5139-2024, 2024. a, b
Oroza, C. A., Zheng, Z., Glaser, S. D., Tuia, D., and Bales, R. C.: Optimizing embedded sensor network design for catchment-scale snow-depth estimation using LiDAR and machine learning, Water Resour. Res., 52, 8174–8189, 2016. a, b, c
Painter, T. H., Berisford, D. F., Boardman, J. W., Bormann, K. J., Deems, J. S., Gehrke, F., Hedrick, A., Joyce, M., Laidlaw, R., Marks, D., and Mattmann, C.: The Airborne Snow Observatory: Fusion of scanning lidar, imaging spectrometer, and physically-based modeling for mapping snow water equivalent and snow albedo, Remote Sens. Environ., 184, 139–152, 2016. a
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., and Vanderplas, J.: Scikit-learn: Machine learning in Python, J. Mach. Learn. Res., 12, 2825–2830, 2011. a
Reynolds, D. S., Pflug, J. M., and Lundquist, J. D.: Evaluating wind fields for use in basin-scale distributed snow models, Water Resour. Res., 57, e2020WR028536, https://doi.org/10.1029/2020WR028536, 2021. a
Roe, G. H. and Baker, M. B.: Microphysical and geometrical controls on the pattern of orographic precipitation, J. Atmos. Sci., 63, 861–880, 2006. a
Rutgers University Global Snow Lab, G.: Snow Cover Extent and Rankings, https://climate.rutgers.edu/snowcover/table_rankings.php?ui_set=1#us (last access: 1 October 2023), 2023. a
Saghafian, B., Davtalab, R., Rafieeinasab, A., and Ghanbarpour, M. R.: An integrated approach for site selection of snow measurement stations, Water, 8, 539, https://doi.org/10.3390/w8110539, 2016. a
Schweizer, J. and Lütschg, M.: Characteristics of human-triggered avalanches, Cold Reg. Sci. Technol., 33, 147–162, 2001. a
Sturm, M. and Liston, G. E.: Revisiting the global seasonal snow classification: An updated dataset for earth system applications, J. Hydrometeorol., 22, 2917–2938, 2021. a
Sturm, M., Taras, B., Liston, G. E., Derksen, C., Jonas, T., and Lea, J.: Estimating snow water equivalent using snow depth data and climate classes, J. Hydrometeorol., 11, 1380–1394, 2010. a
Sturm, M., Goldstein, M. A., and Parr, C.: Water and life from snow: A trillion dollar science question, Water Resour. Res., 53, 3534–3544, 2017. a
Techel, F., Jarry, F., Kronthaler, G., Mitterer, S., Nairz, P., Pavšek, M., Valt, M., and Darms, G.: Avalanche fatalities in the European Alps: long-term trends and statistics, Geogr. Helv., 71, 147–159, https://doi.org/10.5194/gh-71-147-2016, 2016. a
Welch, S. C., Kerkez, B., Bales, R. C., Glaser, S. D., Rittger, K., and Rice, R. R.: Sensor placement strategies for snow water equivalent (SWE) estimation in the American River basin, Water Resour. Res., 49, 891–903, 2013. a
Western Regional Climate Center: Monthly Prevailing Wind Direction Tables, https://wrcc.dri.edu/Climate/comp_table_show.php?stype=wind_dir_avg, last access: 28 June 2022. a
Williams, C. K. and Rasmussen, C. E.: Gaussian processes for machine learning, vol. 2, MIT press Cambridge, MA, ISBN 026218253X, 2006. a
Winstral, A., Elder, K., and Davis, R. E.: Spatial snow modeling of wind-redistributed snow using terrain-based parameters, J. Hydrometeorol., 3, 524–538, 2002. a