the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 18 Apr 2024
| 18 Apr 2024
Data-driven surrogate modeling of high-resolution sea-ice thickness in the Arctic
Charlotte Durand
Tobias Sebastian Finn
Alban Farchi
Marc Bocquet
Guillaume Boutin
Einar Ólason
A novel generation of sea-ice models with elasto-brittle rheologies, such as neXtSIM, can represent sea-ice processes with an unprecedented accuracy at the mesoscale for resolutions of around 10 km. As these models are computationally expensive, we introduce supervised deep learning techniques for surrogate modeling of the sea-ice thickness from neXtSIM simulations. We adapt a convolutional U-Net architecture to an Arctic-wide setup by taking the land–sea mask with partial convolutions into account. Trained to emulate the sea-ice thickness at a lead time of 12 h, the neural network can be iteratively applied to predictions for up to 1 year. The improvements of the surrogate model over a persistence forecast persist from 12 h to roughly 1 year, with improvements of up to 50 % in the forecast error. Moreover, the predictability gain for the sea-ice thickness measured against the daily climatology extends to over 6 months. By using atmospheric forcings as additional input, the surrogate model can represent advective and thermodynamical processes which influence the sea-ice thickness and the growth and melting therein. While iterating, the surrogate model experiences diffusive processes which result in a loss of fine-scale structures. However, this smoothing increases the coherence of large-scale features and thereby the stability of the model. Therefore, based on these results, we see huge potential for surrogate modeling of state-of-the-art sea-ice models with neural networks.
- Article
(12218 KB) - Full-text XML
- BibTeX
- EndNote





Sea-ice models are used to simulate and predict changes in sea-ice cover and their effects on the Arctic and global climate. These models are based on a combination of observational data and theoretical understanding of the physical processes that govern sea-ice dynamics. They are essential conceptual and numerical tools for understanding the past, current, and future states of Arctic sea ice and identifying the key processes that drive its changes.
Here, we present a novel way of making use of data coming from theoretical understanding of the physical processes: based on neural networks, we build a surrogate model for the sea-ice thickness as simulated by the Arctic-wide neXtSIM model (Rampal et al., 2016; Ólason et al., 2022).
Several sea-ice models, like CICE (Hunke et al., 2017) and SI3 (Sievers et al., 2022), are concurrently developed for operational purposes: short-term predictions for maritime route and weather forecast as well as long-term simulations for climate projections. The recent development of models based on brittle rheologies (Girard et al., 2011; Rampal et al., 2016; Dansereau et al., 2016), like neXtSIM, can represent the observed effects of small-scale processes on the resolved mesoscale with ∼10 km horizontal resolution (Bouchat et al., 2022). Small-scale sea-ice dynamics also impact the global sea-ice mass balance (Boutin et al., 2023). Divergent features in the ice, like leads, are associated with localized intense ocean heat loss that enhances sea-ice production in winter (Kwok, 2006; von Albedyll et al., 2022), accounting for about 30 % of the total ice production in the Arctic Ocean. The assumption that models correctly representing the effects of such small-scale processes could also have an advantage in representing the thermodynamics of sea ice is an ongoing topic of research.
Geophysical models are computationally expensive, especially for operational forecasts. However, geophysical models can be partially or completely emulated using data-driven surrogate models. Such surrogate models can speed up the forecasting process once their costly training phase is finished. Notably, the development of more powerful graphical processing units (GPUs) in the past few years favors the use of neural networks for surrogate modeling.
Over the past years, emulating or replacing geophysical models with neural networks has become a promising topic of research, with recent overviews by Bocquet (2023) and Cheng et al. (2023). Emulating ERA5 data (Hersbach et al., 2020), the European Centre for Medium-Range Weather Forecasts (ECMWF) reanalysis product, recent examples of global-scale surrogate models adopt developments from computer vision by using graph neural networks (Keisler, 2022; Lam et al., 2022) and vision transformers (Bi et al., 2022; Nguyen et al., 2023).
By employing convolutional neural network architectures, Y. Liu et al. (2021) and Andersson et al. (2021) successfully showed that probabilistic sea-ice concentration and sea-ice extent can be predicted in a probabilistic way. Furthermore, Horvat and Roach (2022) and Finn et al. (2023b) recently presented neural network approaches to emulate wave–ice interactions and high-resolution sea-ice dynamics. Convolutional long short-term memory (LSTM)-based neural networks were previously investigated by Q. Liu et al. (2021), Y. Liu et al. (2021), and Kim et al. (2020) for sea-ice concentration forecasts.
Encouraged by such examples, we introduce a neural network to emulate the sea-ice thickness from Arctic-wide neXtSIM simulations. Using a convolutional U-Net architecture, we train the network to predict the thickness for a lead time of 12 h based on initial thickness conditions and atmospheric forcings. This surrogate model can then be sequentially applied to obtain sea-ice thickness predictions for seasonal timescales.
We concentrate the surrogate model on the sea-ice thickness, as it is an important quantity for the forecast of sea ice and yet difficult to predict, especially on short timescales (Zampieri et al., 2018; Xiu et al., 2022). Nonetheless, the thickness contains useful information for seasonal forecast (Balan-Sarojini et al., 2021), with direct links to other important quantities, like the sea-ice concentration and sea-ice extent.
Our surrogate model is trained to minimize the ℒ2 error. This type of error metric tends to smooth out features of the fields that lead to double-penalty errors, like leads in sea ice. This diffusion process has been previously observed for deterministic neural networks (Ravuri et al., 2021) when optimized on ℒ2 errors, but also within many forecasting and data assimilation problems in the geosciences (e.g., Amodei and Stein, 2009; Farchi et al., 2016; Vanderbecken et al., 2023). To quantify the diffusion, we propose in this paper an analysis based on power spectral density (PSD).
Section 2 introduces the dataset from which we train the data-driven model and its structure. Section 3 presents the neural network framework, the choices we made about its architecture, and its optimization. Section 4 introduces the metrics for evaluating the results of the surrogate model. Section 5 delivers and discusses the results of the neural network training, forecast skill abilities and advection capabilities of the surrogate model, as well as an analysis of the diffusion phenomenon introduced above. The discussion and conclusions are given in Sects. 6 and 7. The Appendices provide technical information and further illustrations of the results.
Our goal is to train a neural network to emulate the sea-ice thickness (SIT) for a lead time of 12 h. As a training dataset, we extract the SIT from neXtSIM simulations and atmospheric forcings from the ERA5 reanalysis, which we introduce in the following.
2.1 The neXtSIM model and the sea-ice thickness
neXtSIM is a dynamic and thermodynamic sea-ice model (Rampal et al., 2016). It currently uses brittle Bingham–Maxwell rheology (Boutin et al., 2023; Ólason et al., 2022) to emulate the mechanical behavior of sea ice. neXtSIM can represent the observed fine-scale dynamics of sea ice, including its scaling and multifractal properties in space and in time (Rampal et al., 2019; Bouchat et al., 2022). The model is discretized on a Lagrangian triangular mesh. The model output is projected onto a static quadratic grid on which our surrogate model is based. The sea-ice model is coupled with the ocean part of NEMO, OPA (version 3.6, Madec et al., 1998; Rousset et al., 2015). The model configuration is further detailed in Appendix A.
In this study, we only extract the sea-ice thickness, the variable predicted by the neural network. We rely on simulations from 2006 to 2018. As a simulation model area, the simulations use the regional CREG025 configuration (Talandier and Lique, 2021), a regional extraction of the global ORCA025 configuration developed by the Drakkar consortium (Bernard et al., 2006). This area encompasses the Arctic and parts of the North Atlantic down to 27° N latitude with a nominal horizontal resolution of 0.25° (≃12 km in the Arctic basin). The outputs projected onto the static grid can be seen as two-dimensional images with 603×528 grid cells. Without loss of information, we can crop the data to 512×512 grid cells: lower latitudes are removed as well as zones in eastern Europe and North America where no sea ice appears. An example of the simulated sea-ice-thickness snapshot is presented in Fig. 1.
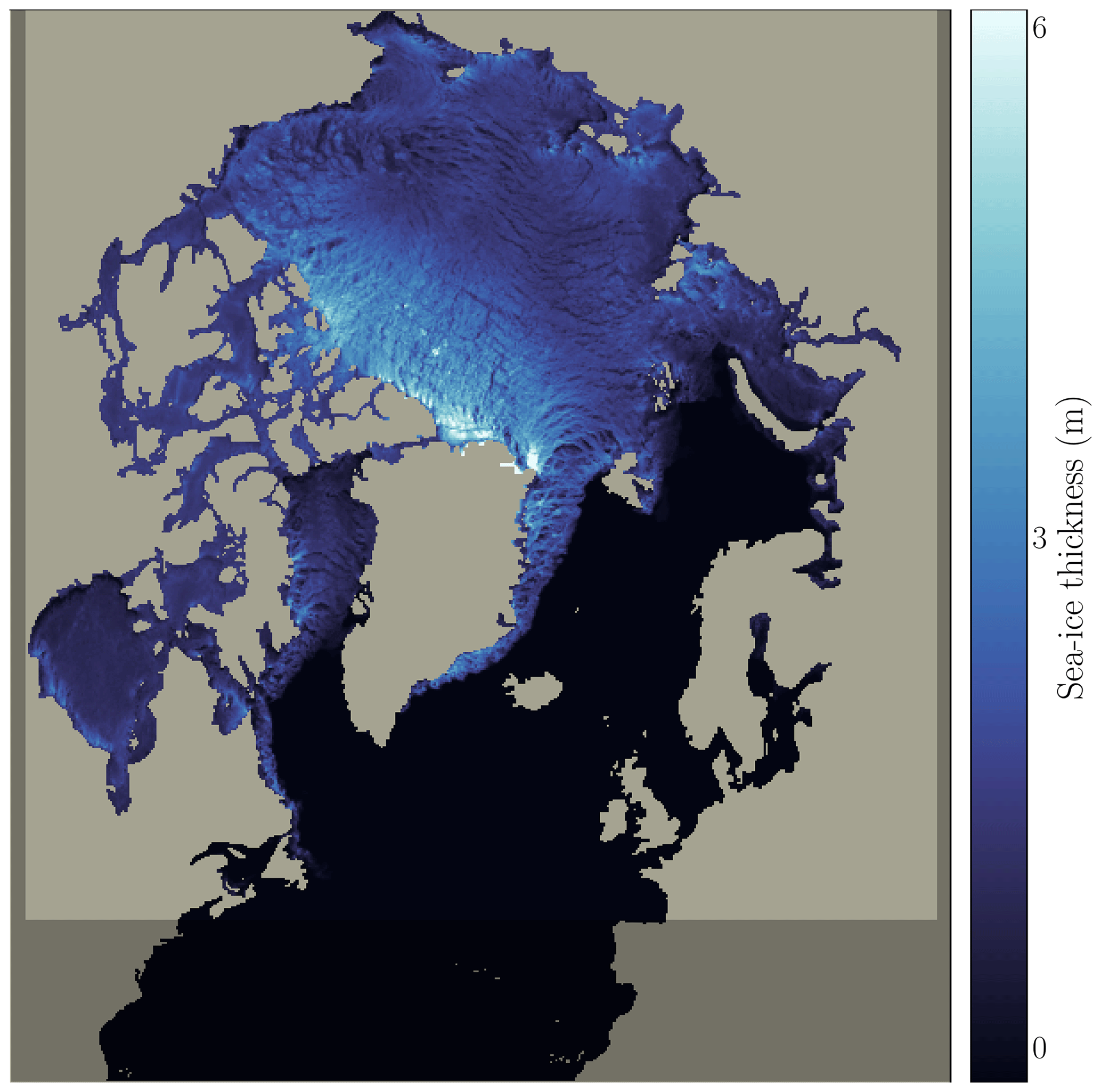
Figure 1SIT simulated by neXtSIM at 15:00 UTC on 3 March 2009. The shaded area represents the cropped grid cells that are further removed in order to keep a 512×512 grid cell SIT field without loss of information.
2.2 Forcing fields
Several atmospheric forcings are added as input fields to the neural network, as the dynamics of the sea-ice thickness are especially driven by the atmosphere (Guemas et al., 2014): the subseasonal to interannual variability in the Arctic surface circulation is predominantly influenced by patterns in the atmospheric wind (Serreze et al., 1992). The atmospheric winds play a crucial role in shaping and driving the circulation patterns of the Arctic Ocean, which in turn affects the movement and distribution of sea ice. Additionally, fluctuations in the atmospheric surface temperature have a significant impact on the Arctic sea-ice variability (Olonscheck et al., 2019). Changes in atmospheric temperature directly affect the growth, melt, and overall state of sea ice in the Arctic region. Warmer atmospheric temperatures accelerate sea-ice melting, leading to reductions in ice extent and thickness, while colder temperatures can promote ice growth and expansion.
Based on these considerations, we supplemented the sea-ice thickness with the 2 m temperature (T2M) and the atmospheric u and v velocities at a height of 10 m (U10 and V10). Those forcings come from the ERA5 reanalysis dataset.
ERA5 forcings are interpolated onto the neXtSIM Lagrangian grid using a nearest-neighbor scheme. Furthermore, to guide the temporal development of the sea-ice forcing times, t+6 h and t+12 h are added as predictors to the neural network, as commonly done in sea-ice forecasting (Grigoryev et al., 2022). We chose to incorporate future forcings based on the understanding that, in sea-ice modeling, the evolution of sea ice is strongly influenced by the atmospheric forcings. In the simulations on which our dataset is based (Boutin et al., 2023), neXtSIM is uncoupled from an atmospheric model and uses ERA5 forcings. In such uncoupled settings, the atmospheric forcing can be given by forecasts and thus be known for the future. Consequently, using future forcings during training is nonrestrictive in terms of its potential operational capability.
Let us note that, for neXtSIM simulations, the atmospheric forcings consist of the two 10 m wind velocity components, the 2 m temperature, the mixing ratio, the mean sea level pressure, the total precipitation, and the snow fraction. We decided to limit ourselves to the first three for our surrogate model. Plueddemann et al. (1998) and Kwok et al. (2013), for example, showed that the sea-ice drift is strongly linked to the wind velocity. Hence, there exists a strong correlation between the atmospheric winds and the sea-ice motion, up to 0.8 in the central Arctic (Thorndike and Colony, 1982; Serreze et al., 1989; Zhang et al., 2000). Those forcings can be a good proxy for the advection of sea ice, which is required to correctly emulate the dynamics of the sea-ice thickness. Note however that T2M forcings from ERA5 are known to have an important bias during the freezing period (Yu et al., 2021; Wang et al., 2019; Køltzow et al., 2022; Nielsen-Englyst et al., 2021). Nonetheless, to stay close to the configuration of neXtSIM simulations, we maintain the ERA5 reanalysis as a forcing. We thus assume perfect knowledge of the forcings, although operational sea-ice forecasts use atmospheric forecasts as forcings.
In this section, we provide a description of the neural network structure, its input and output, the training process, and the various neural networks that were trained. During training, the neural network is trained in a supervised setting. The input to the network consists of the concatenated sea-ice thickness and atmospheric fields, whereas the predicted target is the increment in sea-ice thickness over the subsequent 12 h period. One challenge in training the neural network is dealing with unavailable data points caused by land grid cells. To address this challenge, a technique called partial convolution is employed.
3.1 Preparation of the dataset for supervised learning
Let us represent the sea-ice thickness at time t by . The land-masked grid cells are systematically assigned a value of zero thickness. For small signal levels, the noise induced by the imperfections of the neural network can overshadow the signal contained in the data. Consequently, to increase the signal in the target and decrease the auto-correlation, we chose a lead time of 12 h, even though the data are available at a 6 h frequency.
The neural network is trained to predict the increment in SIT instead of the absolute SIT. The increments of the SIT yt+Δt for Δt=12 h are given by the difference from a persistence forecast.
Based on the current SIT xt and given forcings F, our objective is to construct a neural network fθ(xt,F) with its parameters θ, which predicts the SIT increment :
The neural network is hereby trained to approximate the real increment estimated from neXtSIM simulations (Eq. 1) such that approximately holds.
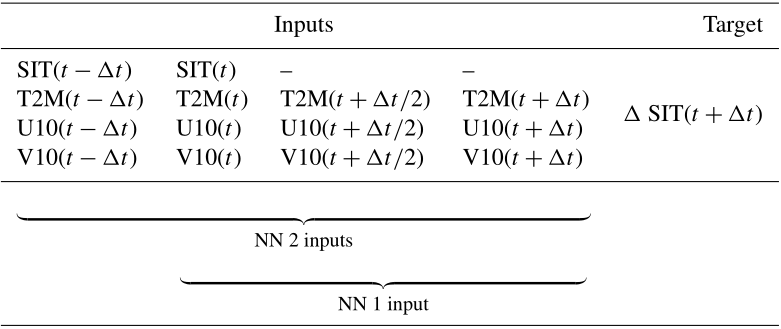
The inputs and target for the neural network are shown in Table 1. In order to represent the temporal development of the sea-ice thickness with the neural network, we also add to the inputs the fields at time t−Δt, both SIT and the atmospheric forcings. When the neural networks are trained on those fields at times t−Δt and t, these are called later “with two inputs”. Otherwise, the neural networks are trained “with one input”, which corresponds to the last three columns of the inputs described in the table.
Table 1Inputs and targets for the neural networks. The table shows the predictors, including sea-ice thickness (SIT) at different time steps, and atmospheric variables: 2 m temperature (T2M) and 10 m wind components (U10 and V10). The target is the increment of the SIT 12 h later (Δt=12 h). The evaluated neural networks use either the last three columns as input, learning with a single time step for SIT (xt) later called neural networks with one input, or all the columns, learning with both xt−Δt and xt later called neural networks with two inputs. Note that, as the SIT is the predicted quantity, there are no SIT values in the inputs for time steps larger than t.
Data from 2009 to 2016 are used for training, giving 11 584 training samples; 2017 is used for the validation of the learned neural network and all the preliminary tests of the surrogate model, and 2018 is used as the year for testing: the results were evaluated once on this year at the end of the study after the hyperparameters were chosen for the neural network. For longer forecasts, to evaluate seasonal forecasts, another test dataset was built from the years 2006, 2007, and 2008.
The input and target data are normalized by a global per-variable mean and standard deviation. These statistics are estimated over the entire training dataset and applied to all the datasets.
3.2 Neural network architecture
Convolutional neural networks (CNNs) are largely used in computer vision and have been shown to be scalable to high-dimensional datasets (e.g., Pinckaers et al., 2022). These networks are based on convolutional layers designed to recognize translation-invariant patterns. In the case of sea-ice thickness, the neural networks need to detect, e.g., leads as well as the marginal ice zone, irrespective of their actual locations.
U-Net (Ronneberger et al., 2015) is an encoder–decoder convolutional neural network architecture with skip connections. In the encoding part, convolutional layers and max-pooling layers are stacked in order to extract spatially more and more compressed features. As convolutional layers are localized by definition, the spatial compression helps the network to extract more globalized features. The number of successive resolution reductions defines the depth of U-Net. At the lowest resolution, the bottleneck, several convolutional layers are stacked with 256 features (channels). In the decoding part, the features are up-sampled through a nearest-neighbor interpolation and convolutional layers. Skip connections couple the encoding and decoding parts at the same resolution level to facilitate training and to retain fine-granular information in the network. This neural network architecture is designed to extract multiscale features, which is known to be notably present in sea-ice dynamics (Rampal et al., 2019). The U-Net used here is described in detail in Appendix C and is schematically outlined in Fig. 2.
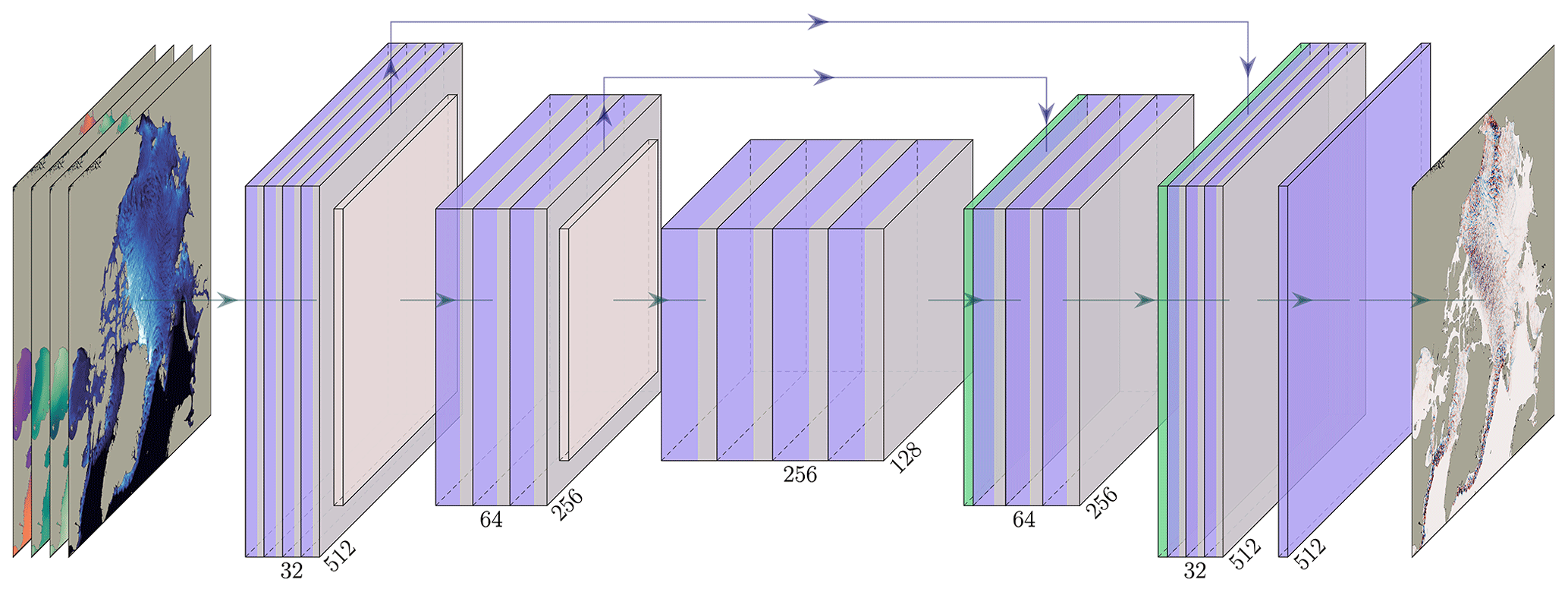
Figure 2Architecture of the U-Net-based neural networks. The U-Net consists of three levels of depth with image sizes of 512, 256, and 128 in the x and y directions. The input of the U-Net includes either 10 or 14 channels, depending on whether only the current time step (xt) or both the current and previous time steps (xt and xt−Δt) are used, alongside their associated atmospheric forcings. The input channels comprise sea-ice thickness, air velocity, and temperature. The number of channels for each convolution is indicated below it, with the first block having 32 channels. The upward arrows represent skip connections, allowing the neural network to retain information from earlier stages and incorporate it into subsequent stages, bypassing the bottleneck.
The last layer of the neural network is a linear function without any activation, as we cast learning of the SIT increment as a regression problem. For all other layers, the mish activation function (Misra, 2019) is used. As opposed to the more-often used rectified linear unit, mish is a continuously differentiable function and has been previously proven to be effective in computer vision tasks (Bochkovskiy et al., 2020; Zhang et al., 2019), demonstrating improvements in training CNNs, particularly in addressing issues such as gradient explosion and gradient dispersion.
3.3 Partial convolution
As we can see in Fig. 1, the information on sea-ice thickness is only defined for ice and ocean grid cells. Land grid cells are masked. When performing two-dimensional convolutions on land cells, the presence of masked values has a detrimental effect on the local averages computed during the convolution operation. The convolution kernels then also include the land cells with an assigned value of 0. One solution is to use partial convolutions (Liu et al., 2018) in every convolutional layer of the neural network. The key idea of partial convolutions is to separate the missing points from informative ones during convolutions, such that the results of convolutions only depend on ocean and ice grid cells; land grid cells are simply omitted in the convolutional kernel. Let us see how it works in a simple example for a single convolution window.
Let us define and b∈ℝ as the weights and bias of a convolution filter. ks is the kernel size of each convolution, always set to 3, except for the last layer of the neural network, where it is set to 1. represents the pixel values (or feature activation values) being convoluted, and is the corresponding binary mask which indicates the validity of each pixel or feature value: 0 for missing (land) pixels and 1 for valid (ocean and ice) pixels. The output of the proposed partial convolution , computed in a convolution window, is then
where ⊙ is an element-wise multiplication and 1 is a matrix of ones that has the same shape as M. In comparison, a normal convolution would be defined as
independent of the validity of the grid cells.
From Eq. (3), we can see that the results of the partial convolution only depend on valid input values (as X⊙M). The scaling factor adjusts the results as the number of valid input values for each convolution varies. It has been used previously in order to recover missing regions from observational datasets (Kadow et al., 2020). In this study, the goal is not to recover data but to avoid artifacts near land caused by underestimation in normal convolutions. The algorithm for partial convolution is further described in Appendix C1.
3.4 Global constraint on loss training
Emulating physical systems with neural networks can lead to a non-physical response (Beucler et al., 2021). In order to reduce a systematic bias of the surrogate model and to ensure that the neural network can correctly predict the global amount of sea ice, we add an additional penalization term to the loss. The non-penalized loss is defined by a pixel-wise mean-squared error (MSE), with x and y two vectors of dimension (Nx, Ny):
The penalization term is defined by the squared difference between the global mean of x and y:
This term weighted against the local loss with the help of a scalar λ is
Let us note that ℒlocal refers to the local dynamics of the sea-ice thickness and that ℒglobal refers to the global dynamics of the sea-ice thickness.
λ is manually tuned to 100. Details on how this value was set are provided in Sect. C3.2. The local loss is approximately 4 orders of magnitude larger than the global loss. By setting λ=100, the global loss represents 1 % of the local loss. In the following parts, we show results for λ=0 and λ=100. The former case will be called unconstrained and the latter constrained.
3.5 Neural network training
The neural networks are trained on a single NVIDIA A100 GPU with a batch size of eight samples. As an optimizer, AdamW (Loshchilov and Hutter, 2017) is used with a learning rate of and a weight decay scheduled with a three-step piecewise constant decay and starting at . If the loss in the independent validation dataset plateaus for 20 epochs, the training is stopped early.
We trained four different neural networks, as described in Table 2. By setting λ to either 0 or 100, we switch the additional loss function constraint on or off, checking its influence on the performance. Additionally, we test whether additional temporal guidance by giving an additional time step as input helps the neural network to predict the increment in the sea-ice thickness.
Table 2Comparison of the trained U-Net-based neural networks in the study. Four neural network configurations are evaluated, varying in the number of inputs and the presence of a constraining term in the loss function. The inputs include either xt alone or both xt−Δt and xt, representing sea-ice thickness and atmospheric variables. The addition of a constraining term in the loss function regulates the neural network based on the global sea-ice thickness.

4.1 Surrogate modeling
To emulate the physical model ℳp, we built a surrogate model ℳs by applying the neural network that predicts the sea-ice thickness increment. Initializing the model with given initial conditions and given forcings F, the surrogate model propagates the sea-ice thickness forward in time, predicting the sea-ice thickness Δt=12 h later:
Note that, for ease of notation, we omit the forcings in the surrogate model notation ℳs. Using the forecasted state as the next initial conditions, we can cycle the surrogate model and predict the sea-ice thickness for longer lead times than Δt:
The forecast at longer lead times is consequently the initial conditions plus a recursive increment term.
Our baseline for the model comparison is constantly predicting the initial conditions without any increment, a so-called persistence forecast; i.e., the sea-ice thickness is unchanged over time. It is a commonly used baseline in sea-ice forecasting, as the auto-correlation of the sea-ice thickness in time is high up to a 1-month lead time (Lemke et al., 1980; Blanchard-Wrigglesworth et al., 2011). We also compare the surrogate model to the daily climatology, computed on a day-of-year basis over the complete training dataset.
4.2 Evaluation metrics for the surrogate
The goal of the surrogate model is to predict as accurately as possible sea-ice thickness over lead times longer than 12 h, i.e., after several iterations of the surrogate model. We define the forecast skill of the surrogate at the kth iteration by computing the root-mean-squared error (RMSE) between the predicted SIT and the actual SIT as simulated by neXtSIM:
The RMSE between the prediction and the simulation xn+kΔt is computed over all valid pixels i of the field of size Nvalid, i.e., pixels which are not land grid cells, for each sample n of the test set containing Ns trajectories initialized at time tn.
The global RMSE is calculated by averaging the RMSE values obtained when the whole sea-ice thickness fields are treated as a single data point. It represents the discrepancy in averaged sea-ice thickness between the prediction and the simulation. By considering the global RMSE, we can assess the performance of the surrogate model in accurately reproducing the average sea-ice thickness compared to the reference model.
In order to quantify systematic errors of the surrogate model, we compute its mean error (bias). This metric tells us about the ability of the neural network to correctly estimate the total amount of sea ice in the full domain:
The sea-ice extent (SIE) can be derived from the sea-ice thickness. We define a threshold σacc=0.1 m for the SIT (see Appendix B for its definition) above which a grid point is considered sea ice. By obtaining a classification mask between ice and no ice, we can easily define an accuracy metric based on the SIE. Similarly to the ice-integrated edge error defined by Goessling et al. (2016) on sea-ice concentration, we define a metric which counts the pixels where the surrogate model disagrees with neXtSIM on the presence or not of sea ice. Two terms are defined: the first one indicates the number of pixels where overestimates the presence of sea ice, and the second one is where the surrogate model underestimates the presence of sea ice compared to neXtSIM. The accuracy is averaged over all the Ns samples:
4.3 Quantification of the diffusion effect
Diffusion can impact the accuracy and fidelity of the surrogate model's predictions. Excessive diffusion may lead to the loss of important details and reduce the model's ability to capture complex patterns. By quantifying diffusion, we can evaluate the model's performance and how the diffusion process evolves with increasing lead time.
To analyze the smoothing of features across multiple iterations, we want to find a metric that can describe the evolution of these features across different scales. Mathematicians have proposed several metrics for quantifying multifractality, such as box-counting algorithms and fractal dimensions (Xu et al., 1993). For two-dimensional geophysical fields, the PSD has the ability to detect spatial properties over the different space scales (Lovejoy et al., 2008). This quantity allows for a quantitative assessment of the changes in the features and its multiscale distribution as a function of the forecast lead time. Let x be a snapshot of the sea-ice thickness at a given time, either from neXtSIM or from the surrogate model. We define the PSD of x by
where dft(x) is the discrete Fourier transform of x. The PSD P is indexed by the spatial wave numbers kh and kv. The energy as a function of the wave vector is in turn related to P via
The power-law behavior of a field's energy spectrum can be caused by the underlying self-similarity or fractal nature of the image. Fractals are patterns or objects that display similar structures and statistical properties at various scales. In the case of an image, this means that certain statistical characteristics, such as texture or pixel intensity variations, repeat themselves across different scales. This energy spectrum can be identified with a power law:
where β is called the spectral exponent and C the normalization constant. Details of the computation of the spectral exponent are provided in Appendix D5. The power-law nature of the energy spectrum reflects the scaling properties of the field, where the statistical variations remain consistent regardless of the scales being observed. The power-law exponent β determines the degree of self-similarity and how quickly the energy decreases as the frequency or spatial scale increases.
We define the spectral exponent ratio Qβ after t iterations by
which is the average over the full testing set of the ratio between the spectral exponent of predicted fields from the surrogate model and the spectral exponent of the fields as simulated with neXtSIM at the same time. If the surrogate model exhibits processes which lead to over-diffusion, then the spectral exponent of the predicted SIT should be larger than that of the actual SIT, resulting in a ratio Qb>1. Hence, the ratio corroborates the emergence of diffusion in the forecast.
5.1 Short-term forecasting
In this paragraph, we assess the performance of the surrogate model on a short-term timescale, specifically up to a 1-month lead time. The metrics mentioned in Sect. 4.2 are computed using the 2018 test dataset. They are reported in Table 3.
We believe that the global RMSE serves as a proxy for the consistency of the surrogate model, which we define as the averaged sea-ice thickness in the domain. Based on this idea, we anticipate that the globally constrained neural network will demonstrate improved performance for forecast lead times exceeding 12 h.
Table 3Statistical indicators to assess the performance of the surrogate models. The table shows the results for two lead-time scenarios: 12 h and 15 d. Two types of surrogate models are evaluated: those with one input (representing sea-ice thickness at time xt) and those with two inputs (with SIT and atmospheric forcings at time ). The models are trained with and without the addition of constraints, represented by a regularization parameter (“Constraint”). The evaluation metrics include the RMSE, global RMSE, and SIE accuracy (ACC). Climatology and persistence baselines are included for comparison. Bold numbers indicate the best-performing model in a given column.
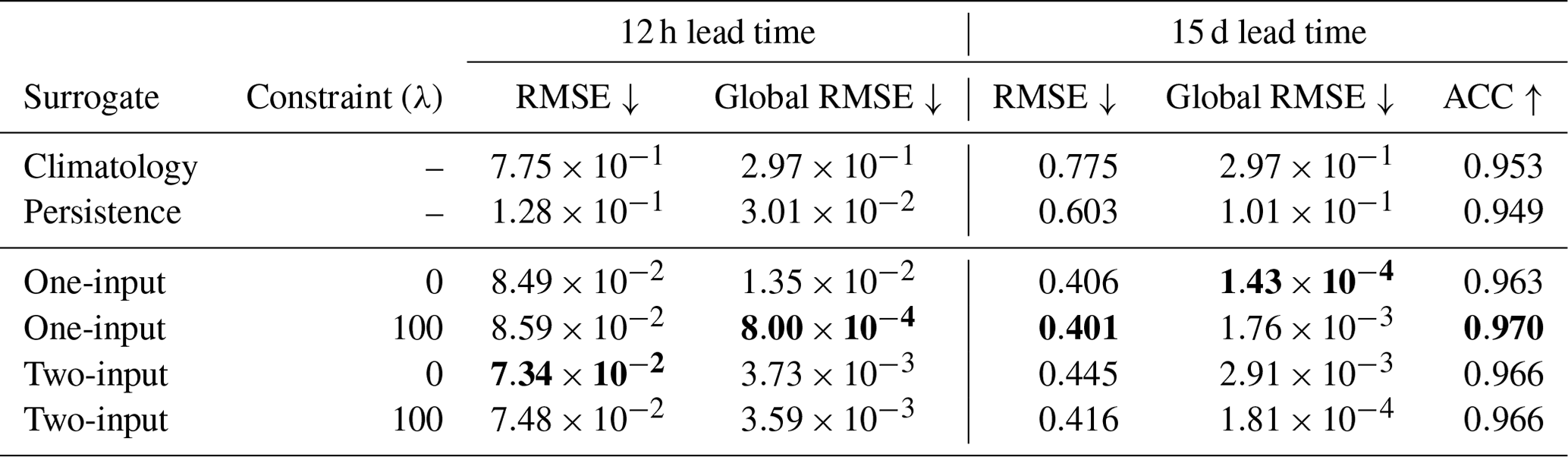
The introduction of a global penalization term into the constrained neural network reduces the global RMSE by 1 order of magnitude within 12 h compared to the absence of penalization. However, the impact of the global loss term (as defined in Eq. 6) is relatively small on the classical RMSE, as defined in Eq. (11), compared to the influence of including additional time steps.
On average, for the constrained neural network with one time step as input, we observe a 33 % improvement after a lead time of 12 h and a 33 % improvement after 15 d over the persistence on the RMSE. For the constrained neural network with two time steps in the input, we observe a 41 % improvement after 12 h and a 31 % improvement after 15 d over persistence. It is worth noting that all the surrogate models exhibit significant improvements over climatology in forecasting sea-ice dynamics for a 15 d period. On average, these improvements amount to a 46 % enhancement compared to relying solely on climatology-based predictions for the RMSE. Adding the penalization term slightly increases the RMSE of the surrogate after 12 h but improves the RMSE after 15 d (see Fig. 3a for the comparative evolution of the RMSE for one input up to a lead time of 25 d). The major improvement of adding the penalization term comes from the global RMSE, which is reduced by a factor of 9 after 12 h. Regarding the two-input surrogate, the impact on the global RMSE after 12 h is only 4 %. The global RMSE is much more volatile during training, being smaller than the local RMSE. In the case of the two-input NN, the unconstrained model had a given global RMSE which happened to be similar to the model trained with the constraint despite not being trained with the global term. The fact that the results are still better in the constrained case after 15 d is also proof that the model improves with the global loss term.
We note that the global RMSE after 15 d is better on average for the unconstrained surrogate. However, as seen in Fig. 3, the strong advantage of the constrained surrogate is the important reduction of the bias standard deviation, represented transparently in panel (b). This improvement is further supported by evaluating the averaged SIT over the entire year, as illustrated in panel (c). During periods of significant sea-ice production and melting, the surrogate model with the global constraint exhibits a closer alignment with the neXtSIM output, indicating a higher level of accuracy. These findings suggest that integrating a global constraint term during the optimization process enhances the surrogate model's ability to capture and reproduce the complex dynamics associated with sea-ice formation and melting.
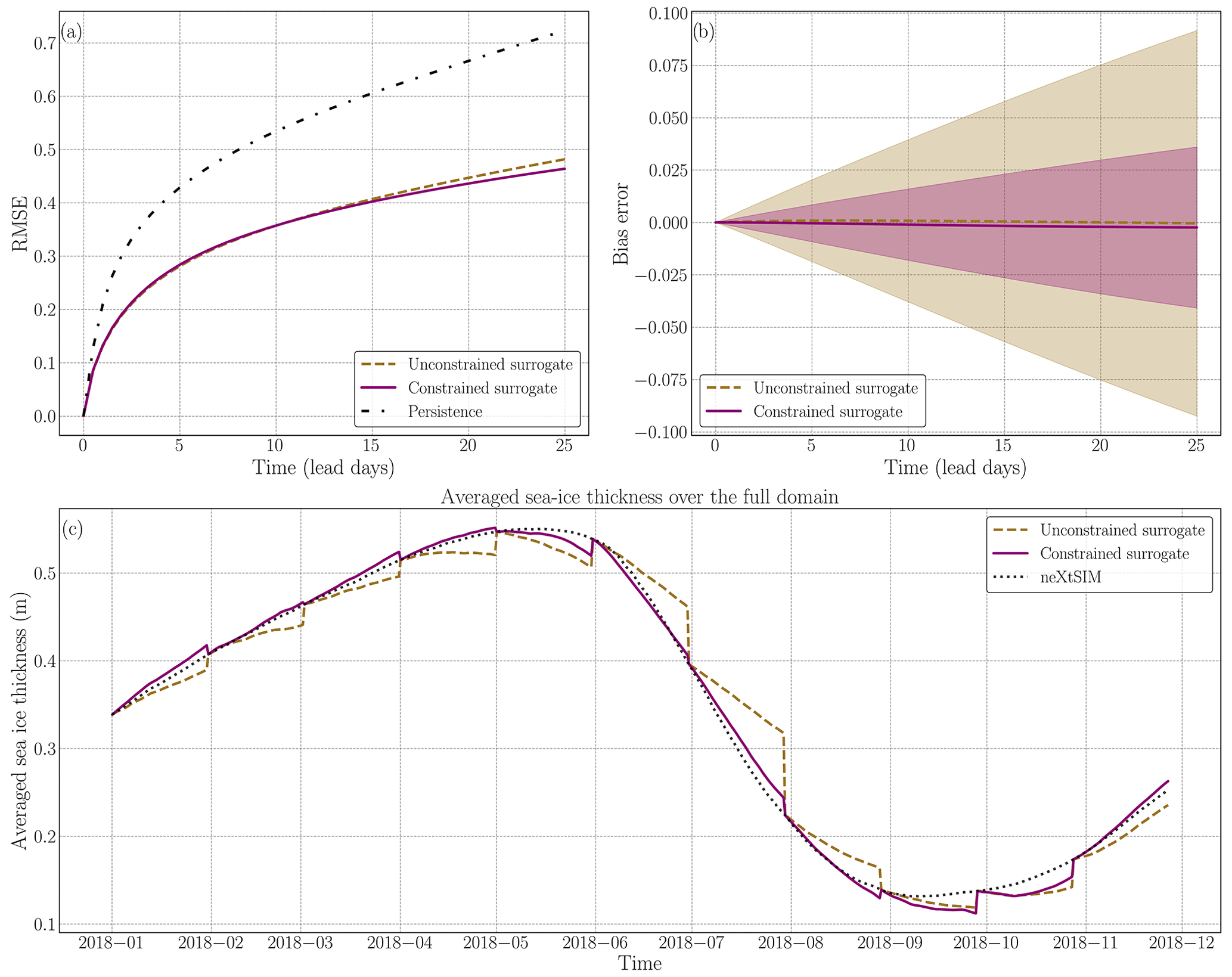
Figure 3Analysis of the additional constraint during neural network training on the surrogate model over several iterations. In panel (a), the forecast skill of the surrogate model is depicted with solid lines representing the average. The unconstrained neural network is represented by the brown dashed line, while the constrained network is shown in purple. The black dotted line represents persistence. Panel (b) displays the bias error associated with the surrogate, and the standard deviation is represented in transparency to outline the variance reduction of the constrained surrogate. In panel (c), the global conservation of sea ice is plotted. The full-year trajectory is constructed by concatenating 60 forecast iterations. Every 30 d, the forecast is initialized using neXtSIM at the corresponding time and run for 60 iterations. The surrogate models are compared to the neXtSIM output over the same period.
As the neural network is trained for a 12 h lead time, the first iteration of the surrogate model corresponds to its targeted lead time. In this first iteration, we observe that stacking two time steps in the inputs of the neural network improves the surrogate by 13 % in terms of RMSE. In preliminary tests, we observed no further gain in performance with more than two time steps as input.
The forecast skill for a lead time of up to 25 d highlights the overall improvement of the constrained surrogate model compared to the persistence forecast (Fig. 4), as similarly observed in Table 3. For the constrained surrogates, the two-input surrogate gains 14 % after 12 h over the one-input surrogate, but the results are reversed after 15 d, with a 3 % improvement for the one-input surrogate, as we can also observe in Fig. 4. Even if those results would favor the surrogate model with two inputs, biases for either one or two inputs are close to zero and are thus acceptable. It is expected that the neural network will give a better RMSE with more inputs in the neural network. We hypothesize that increasing the number of inputs leads to a bigger accumulation of errors being introduced into the input data when we predict with the surrogate model, since the model was non-auto-regressively trained on perfect input data. In other words, as we cycle the neural network, the predictions from previous iterations are used as inputs for subsequent iterations, so that if there are errors or inaccuracies in these predictions, they can propagate and accumulate over time, potentially leading to a degradation in the quality of the outputs. As the surrogate learns the dynamics with “perfect” conditions, we increase the error of the inputs by having two time steps as the input of the neural network after several iterations. Even if the two-time-step neural network provides better results for the first iterations and for the global RMSE, it seems more relevant to focus on longer lead times for model selection. In the next paragraphs, we only present results for a surrogate model with one time step in the input.
The evaluation of SIE accuracy supports and strengthens our previous findings, providing additional evidence for the reliability of the results. In particular, we observe that the constrained neural network with one time step as input consistently outperforms other models in predicting SIE. The higher accuracy achieved by the constrained neural network with one time step as input suggests that this configuration effectively captures the relevant information and patterns necessary for accurate sea-ice dynamics prediction. This indicates that the specific constraints imposed during training, along with the inclusion of a single time step as input, contribute to better understanding and modeling the underlying dynamics of SIT. The consistent performance of this model across different evaluation metrics (see Table 3 and Figs. 3 and 4) and scenarios further validates its reliability and robustness. This surrogate configuration is able to capture the essential features and patterns of SIT dynamics, enabling more accurate predictions compared to other configurations.

Figure 4Comparison of the root mean square error (RMSE) between the constrained surrogate models for either one (purple solid line) or two inputs (green dashed line) and the persistence (black dotted line) approach for SIT prediction over a 25 d forecast horizon. While the one-input surrogate yields better results in terms of RMSE for more than 5 d, the surrogate with two inputs gives better results at the beginning of the forecast, as can be observed in the zoom window.
Despite its ability to predict sea-ice thickness over the full domain, the forecast skill is not homogeneous over the different regions of the Arctic. The delimitation of the region from the National Snow and Ice Data Center was interpolated on the neXtSIM grid to then compute the forecast skill in the different regions (see Fig. 5) and numerical results for 25 lead days in Table 4. In the central Arctic, the surrogate forecast skill has an improvement of the RMSE of 31 % on average for a 25 d lead time over the persistence. The variability of the forecast skill is equal to 0.0590 and is 34 % lower than the variability of the persistence after the same lead time. In the Greenland Sea, the forecast skill of the surrogate is 35 % better than persistence for a 25 d lead time. The forecast skills of both the persistence and the surrogate are on average low because of the number of sea-only pixels in this region during the full year. In every region, we systematically observe an improvement in both RMSE and its standard deviation of the surrogate over the persistence. This means that we improve over most samples the ability of the surrogate to predict the dynamics across all the regions. Notably, the Beaufort Sea exhibits a higher RMSE compared to the other regions. This discrepancy prompts further investigation into the surrogate model's limitations in accurately predicting sea-ice dynamics near land in this region.
Table 4Comparison of RMSE and its standard deviation (σRMSE) between the surrogate model and persistence for different regions. The table presents the mean RMSE and σRMSE values for the central Arctic, Greenland Sea, East Siberian Sea, Kara Sea, and Beaufort Sea as defined in Fig. 5a. The RMSEs are computed for a lead time of 15 d.
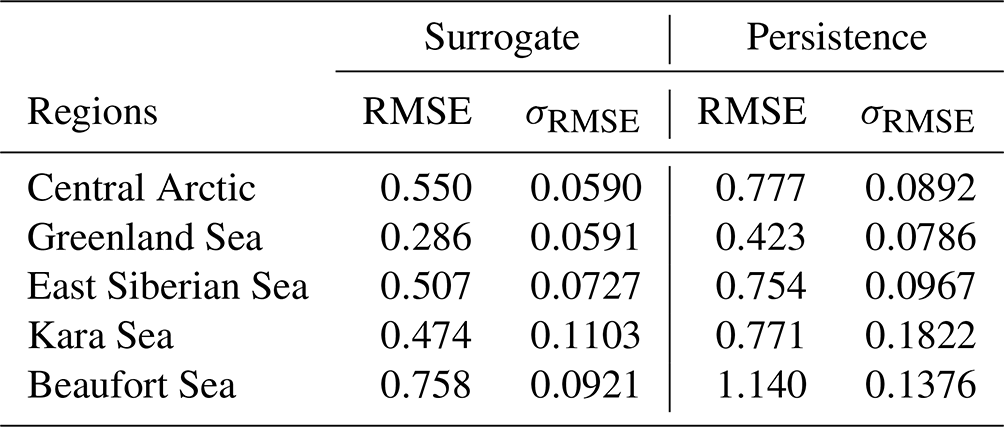

Figure 5Regional forecast skills. Panel (a) illustrates the delineation of the regions used for computing the regional forecast skill. Panels (b) to (f) show the averaged forecast skill over the full test year for specific regions: (b) central Arctic, (c) Greenland Sea, (d) East Siberian Sea, (e) Kara Sea, and (f) Beaufort Sea. The purple solid line represents the surrogate model forecast skill, while the black dashed line represents persistence.
5.2 Advection
The surrogate model exhibits favorable advection properties encompassing both large-scale and fine-scale dynamics. This successful advection can be attributed to the incorporation of atmospheric forcings in the model. The atmospheric forcings, which capture the influence of atmospheric conditions such as winds and temperatures, play a crucial role in driving the movement and behavior of sea ice.
The thickness field and the SIE are represented in Fig. 6a for neXtSIM and in Fig. 6b for the surrogate. Additional SIT fields are presented in the Appendix for a lead time of 5 d and a lead time of 25 d in Figs. D2 and D3. The surrogate model seems to correctly advect the sea-ice sheet on the large scale. The inclusion of atmospheric forcings as inputs to the surrogate is crucial for capturing and learning the driving dynamics of sea ice. When training the surrogate model without incorporating any atmospheric forcings, the absence of advection becomes apparent. Without the driving influence of atmospheric conditions such as winds and temperatures, the surrogate model lacks the necessary information to simulate and reproduce the advection of sea ice, and it tends to exhibit behavior similar to persistence.

Figure 6Evaluation of the advection from the one-input constrained surrogate model. (a) neXtSIM SIT on 30 May 2018, with zoomed regions indicated for panels (c), (d), (e), and (f). (b) Surrogate model output on 30 May 2018 after a 30 d forecast initialized on 15 May, with sea-ice extent (SIE) computed from neXtSIM (red) and the surrogate (yellow). Similar delimitation of sea-ice edges is observed in both curves. Panels (c), (d), (e), and (f) depict manual feature tracking in different Arctic regions: (c) MIZ in the Greenland Sea, (d) Beaufort Sea, (e) central Arctic, and (f) Barents Sea. The trajectories for 30 d are shown in purple for neXtSIM and in white for the surrogate model.
In order to verify this visual impression, we manually followed four remarkable features: (c) on the MIZ, (d) a feature in the Beaufort Sea, (e) a persistent crack in the central Arctic, and (f) on the MIZ in the Barents Sea for 1-month prediction. We compared the motion of those features between the surrogate model and the actual neXtSIM dynamics. The results depicting the sea-ice advection are illustrated in Fig. 6c, d, e and f. Notably, several features, particularly in the MIZ, demonstrate nearly identical displacements over this 1-month period. These features appear to be accurately captured and reproduced by the surrogate model, reflecting its ability to simulate the advection of sea ice. Slight deviations in trajectories are observed for features such as cracks within the sea ice, but these differences do not indicate incoherent or erratic behavior: the trajectories keep similar paths, which could be due to the advection of the features by atmospheric forcings.
5.3 Diffusion quantification
The observation of a smoothing effect on fine-scale features which increases with the forecast lead time aligns with the ℒ2 optimization of a deterministic neural network: while scoring well, the surrogate model can deviate from the genuine physics with a prominent smoothing of the fine scales. The goal of training is to minimize the MSE, which entails reducing discrepancies and errors by creating an average over the features. This smoothing effect can be seen in Fig. 7. While the surrogate model is able to predict the global and local advection patterns of sea ice, it tends to average out the fine-scale features over successive iterations. The observed smoothing effect highlights the trade-off between capturing large-scale dynamics and preserving fine-scale features in the surrogate model. While the model may sacrifice some fine-scale details, it still retains the essential advection patterns and provides reliable predictions on a global scale.
This smoothness can be quantified by computing the PSD (Hess et al., 2023; Neuhauser et al., 2022) and the Qb ratio as defined in Sect. 4.3. The results are presented in Fig. 8. After 12 h, the PSD of neXtSIM and the surrogate are close: the surrogate model exhibits similar multiscale properties to the physical model. We found the spectral exponent to be a good quantitative measurement of the diffusion process of the surrogate model. As the number of iterations of the surrogate model grows, we observe that the smoothness of the field increases. This means that we lose information at high frequencies, and thus the PSD decreases for high frequencies (see Fig. 8b). This reduction for high frequencies further supports the notion that the diffusion processes within the surrogate model lead to a loss of detailed information and finer-scale features. When computing β, we see a fast increase in β when the number of cycles increases (see Fig. 8c). At a 10-lead-day time, we have an increase in the β exponent of 6 % averaged over the full year. Interestingly, the spectral exponent does stabilize after 20 lead days and then slowly decrease. We hypothesize that the neural network has reached its highest possible resolution for a correct representation of sea-ice advection at the global scale by reducing the inherently chaotic and stochastic fine-scale dynamics. In other words, the surrogate model is able to correctly advect sea-ice thickness up to a given resolution, beyond which smoothing the fine-scale dynamics yields lower RMSEs.

Figure 7Comparison of neXtSIM (a) and surrogate (b) runs for a 25 d period in the central Arctic. The fine-scale dynamics observed in panel (a) are smoothed in the surrogate model (b).
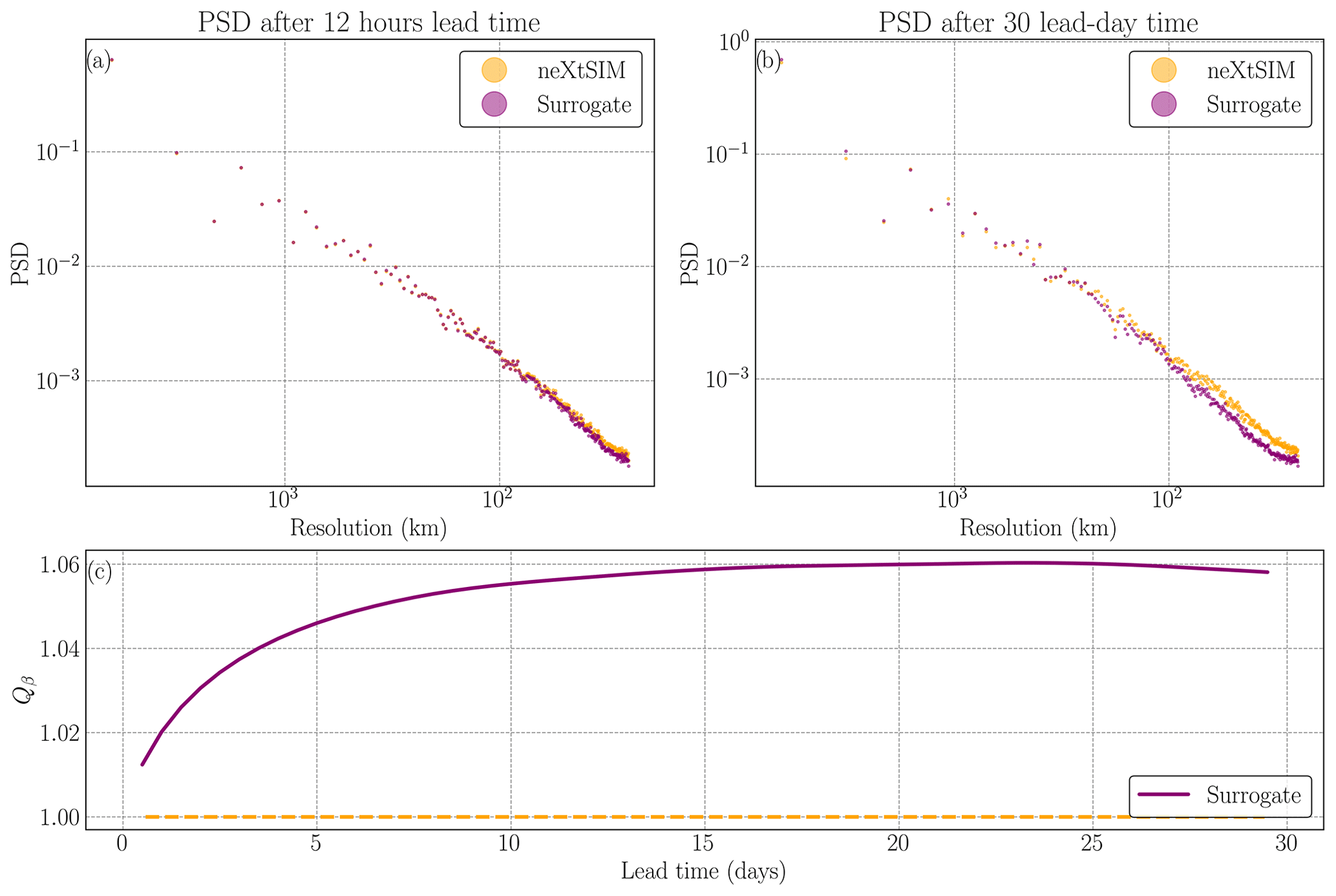
Figure 8Evaluation of the power spectral density (PSD) and diffusion process in surrogate modeling. (a) PSD of one neXtSIM output (orange points) and one surrogate output after 12 h (purple points), indicating a close match. (b) PSD after a 30 lead-day time of the surrogate model compared to neXtSIM at the same time, showing lower values for high spatial frequencies in the surrogate model. (c) Qβ values quantifying the diffusion process for the surrogate, with the orange dashed line representing neXtSIM for comparison.
5.4 Long-term forecast
In this section, we discuss the ability of the surrogate model to forecast the dynamics of sea-ice thickness at a seasonal scale, focusing on the constrained one-input surrogate model. Seasonal forecast of Arctic sea ice is complex (Sigmond et al., 2013) and even more so on a high-resolution grid. While previous results were presented with at most 60 iterations of the surrogate model, here we present runs of the surrogate with 720 iterations which correspond to 360 d forecasts of sea-ice thickness. Those forecasts are initialized from January 2006 to January 2008, with initial conditions sampled every 30 d. In total, we have 25 runs of 360 d to evaluate the surrogate model (see Fig. 9). In Appendix D2, we show some snapshots of the seasonal forecast model over the full year, accompanied by the SIE delimitation (see Fig. D4). The surrogate model is stable over the full year, and the RMSE is lower than that of the daily climatology for 6 months. In the bottom panel of Fig. 9, the global averaged SIT for the surrogate model aligns with both the neXtSIM output and the climatology-based approach. The non-negligible bias of the climatology comes from the fact that the daily climatology is computed over 2009–2016 and is directly linked to sea-ice thinning. This consistency can be attributed to the low bias exhibited by the constrained surrogate model (see Fig. 3). The constrained model's low bias helps maintain a physically realistic behavior of the sea ice, even during long-term forecasts. The low error values of the bias observed during each iteration contribute to maintaining the physical integrity and conservation of the sea ice in the surrogate model. This indicates that the surrogate model's predictions remain consistent with the overall dynamics of sea ice, supporting its ability to capture the essential characteristics and behavior of the system. However, it is worth noting that, when testing the surrogate model on a 2-year forecast, difficulties were encountered in accurately predicting the dynamics beyond 1 year due to the constant, albeit slow, increase in the error of the surrogate.
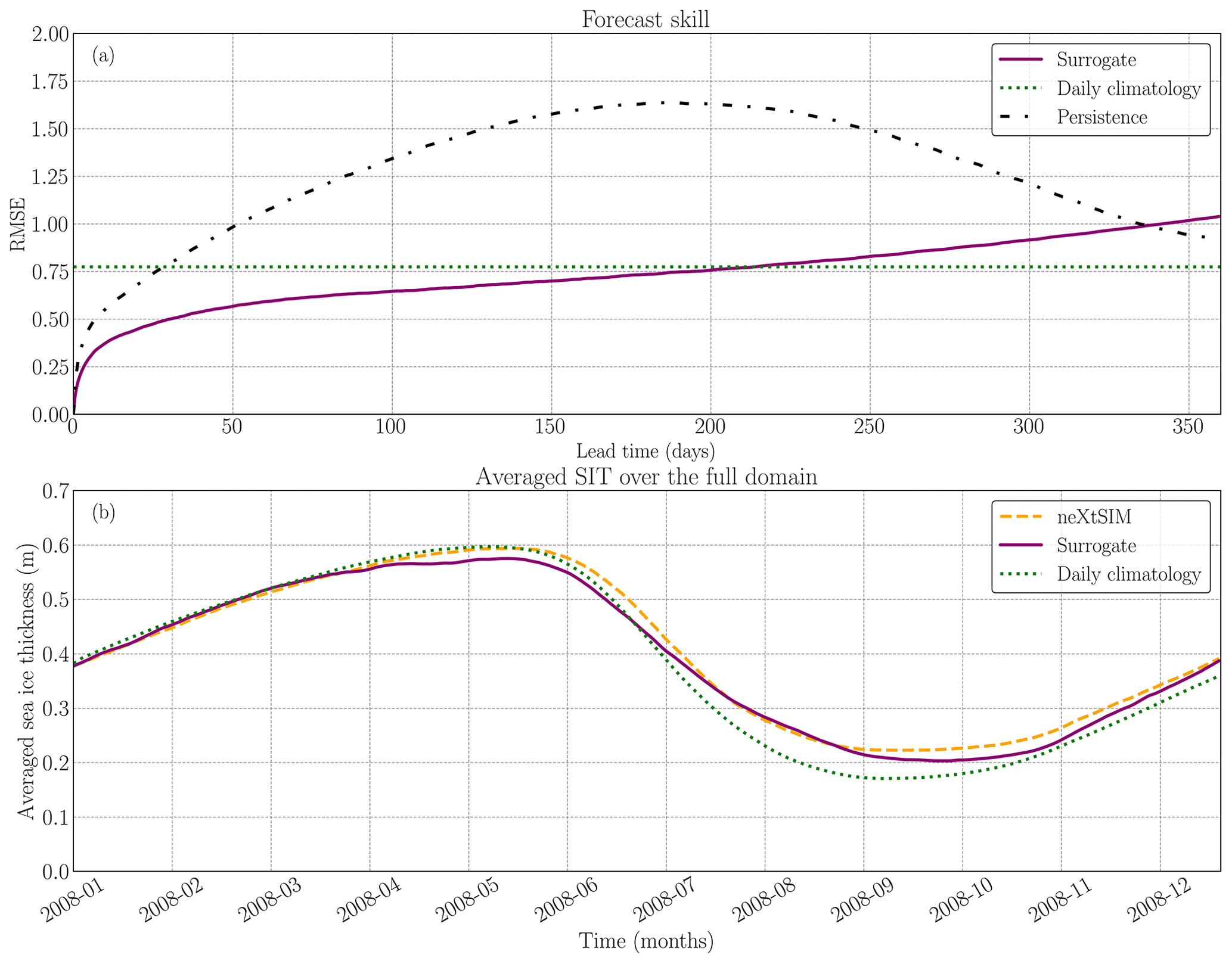
Figure 9Performance evaluation of the constrained surrogate model and comparison with the persistence and climatology for seasonal forecast. (a) Forecast skill of the constrained surrogate model for 1-year long forecasts, based on 25 runs with different initialization times. The surrogate model (solid purple) is compared against persistence (dashed black) and daily climatology (dotted green). (b) Global averaged sea-ice thickness throughout the year, starting in January 2008, comparing the surrogate model (solid purple), the physical model neXtSIM (dashed orange), and the daily climatology (dotted green). The seasonality of the SIT is well-preserved by the surrogate.
In terms of SIE prediction, the surrogate model demonstrates the capability to accurately forecast the edge of the sea ice throughout the year, regardless of the initialization period, as shown in Fig. 10. As anticipated, the surrogate model performs significantly better than persistence during periods of high variation, particularly during summer and fall. In periods where the ice edge is almost static, persistence is a good baseline prediction for the position of the ice edge. While our surrogate model still correctly advects SIT, the results for the SIE accuracy do not differ much from those of persistence. Indeed, since the SIE is post-processed from SIT and only partially relies on the position of the MIZ, we lose most of the benefit of a correct SIT prediction by the surrogate model.
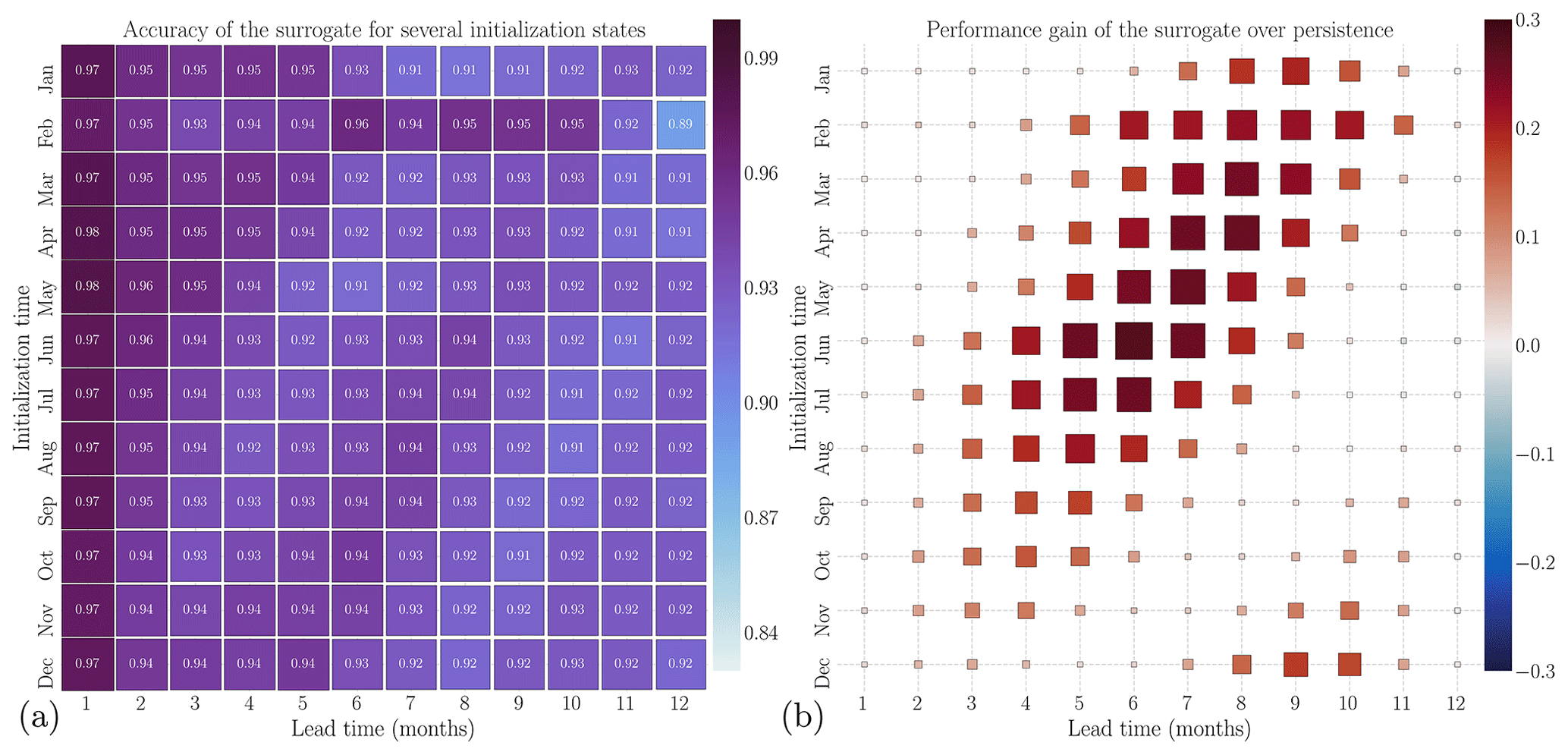
Figure 10Estimation of the sea-ice extent forecasting performance for different initialization times and forecast horizons. Panel (a) illustrates the sea-ice extent (SIE) accuracy on the 2006–2008 test dataset with varying initialization times. Panel (b) displays the relative difference between the SIE accuracy of the surrogate model and persistence.
Even though it is a useful marker for the Marginal Ice Zone (MIZ), this post-processed variable is inadequate for representing large-scale dynamics of SIT, e.g., in the central Arctic. It only compares the position of the ice edge and removes the information about global motion of sea-ice thickness inside the ice sheet.
6.1 Fast emulation of the high-resolution SIT
Our proposed surrogate model based on a U-Net neural network can emulate the large-scale sea-ice thickness as simulated by neXtSIM on daily and seasonal timescales. The main advantage of the emulator is the computational time needed for a forecast. Once the neural network is trained, computing one iteration of the surrogate, a 12 h forecast, takes approximately 72 ms on a single NVIDIA A100 GPU. A forecast for 1 year takes under 1 min. This opens the perspective to run a large ensemble of simulations for complex sea-ice models, which could facilitate data assimilation. However, the observed smoothing effects might cause a collapse of the ensemble for longer lead times. This would require further analysis or a subsequent improvement of the surrogate model.
Note that the training of the neural network remains slightly costly, around 18 h on a single NVIDIA A100 GPU. Approximately 10 000 h on NVIDIA A100 GPUs were necessary to conduct this study.
Training a surrogate model for a coarser resolution is faster. However, a surrogate model for high resolutions can resolve more processes. To showcase this, we display results for additional experiments on a coarse-grained dataset with 128×128 grid cells compared to 512×512 grid cells at high resolution. The neural network has the same configuration as the high-resolution dataset and follows the same training procedure. To compare the surrogate trained on the high-resolution dataset to the surrogate trained on the aforementioned coarse resolution, we plot the root-mean-squared error (RMSE) for both resolutions in Fig. D1. Surrogate modeling at high resolution decreases the RMSE by 31 % after 12 h compared to the coarse surrogate. This improvement similarly holds throughout the resolution levels and also for longer lead times. Since this improvement is visible at all resolutions, it can be linked to a better representation of the small-scale dynamics and their impacts on larger scales for the high-resolution surrogate. While the training and inference of this high-resolution surrogate model are significantly more time-consuming than the coarse-grained surrogate, it is still about 100 times faster than physical model simulations. Consequently, we see a gain from using high-resolution data for surrogate modeling, even if the surrogate leads to smoothed-out forecasts.
6.2 Architecture of the neural network
Several neural networks have been investigated on a lower-resolution setup by coarse-graining the dataset down to a 128×128 grid-cell array. In this lower-resolution setup, both the ResNet (He et al., 2016) and ConvLSTM (Shi et al., 2015) architectures have been studied, yielding quite similar results in terms of forecast skills on the validation dataset. From our experiments, the specific architecture of the convolutional neural network does not matter much. The LSTM-based approach with a lag of 48 h led to satisfactory forecast skills but, because of the high training costs (441 s per epoch) compared to U-Net (108 s per epoch), we chose to focus on the U-Net structure for the high-resolution dataset. Regarding the ResNet architecture, also implemented with partial convolution, the results were also quite similar despite higher training costs (172 s per epoch).
6.3 Smoothness of the fields and deterministic neural networks
Using the power spectral density as a quantification of the diffusion shows that the diffusion process reaches a threshold. By omitting the inherently chaotic fine-scale dynamics, which exhibit stochastic behavior, the surrogate model achieves a balance between capturing the essential large-scale patterns and minimizing the impact of unpredictable fluctuations: chaotic and stochastic processes lead to high sensitivity to initial conditions, making these processes difficult to model accurately. By prioritizing the larger-scale dynamics and averaging out fine-scale features, the surrogate model mitigates the influence of these chaotic and stochastic processes. This mitigation results in more stable and reliable predictions on a global scale. This hypothesis implies that the surrogate model focuses on capturing the dominant advection patterns that drive the overall behavior of sea ice while sacrificing some of the finer details. While this trade-off may result in a loss of information for fine-scale dynamics, it allows the model to provide valuable insights into global-scale advection patterns.
The smoothing effects are directly linked to the training of the neural network as a deterministic surrogate model. We can expect less smoothing for better models as the uncertainty is decreased. However, due to the availability of the training data and computational considerations, we focus on predicting lead times of 12 h, and there are always situations that cannot be predicted from the available data. By maintaining a deterministic neural network, there will consequently be a smoothing effect, and we generally do not anticipate significant improvements in the quality of the details. By adapting generative neural networks, however, the surrogate model could learn to properly sample from the forecast distribution and hence increase the level of fine-scale details (Ravuri et al., 2021). It is worth noting that generative models and especially denoising diffusion models are currently under investigation by different teams for diverse geoscientific problems (e.g., Finn et al., 2023a; Leinonen et al., 2023; Mardani et al., 2023; Price et al., 2023). Nonetheless, the training of such models is notoriously more difficult than that of deterministic models.
Smooth fields are good in terms of RMSE. Caused by the discrete-continuous sea-ice processes, the RMSE might not be an optimal evaluation metric. Training for other metrics can become increasingly more complicated and would exceed the scope of the study. Furthermore, the surrogate model is statistically driven, whereas models like neXtSIM are based on our physical understanding. Such models based on physical principles can have advantages, especially for future cases where we have an extrapolation task caused by climate change.
6.4 Seasonal forecasts
Regarding seasonal forecasts, the model is stable for lead times of up to 1 year, even if the climatology has a smaller forecast error after 6 months. Our surrogate can conserve the average sea-ice thickness over a full year, while also represents advection. This indicates that our surrogate model can capture the large-scale dynamical and thermodynamical evolution of the sea ice over the full year. These phenomena are driven by external forcings from the atmosphere and ocean. However, the surrogate model can represent the influence of the forcing on SIT, something that a climatology and, especially, a persistence forecast cannot exhibit. Furthermore, for short-term forecasts, the surrogate model consistently outperforms persistence and the daily climatology, and it shows better forecasts than a daily climatology for more than 6 months in terms of forecast skill.
6.5 Towards data assimilation and multivariate emulation
The implementation of the surrogate model as a neural network allows us to easily compute its adjoint. Thus, we could use a four-dimensional variational (4D-Var) data assimilation scheme. Our current 4D-Var approach under investigation uses the surrogate model primarily for short-term forecasting. Despite the smoothing effect, we believe that the utilization of the adjoint could prove beneficial.
The definition of an adjoint is meaningful for the sea-ice thickness on the projected grid. While performing variational data assimilation on this grid poses no issues, it is important to acknowledge that the constructed adjoint would differ from the one of neXtSIM on the original triangular mesh. However, a common approach in operational variational data assimilation is to apply inner and outer loops (e.g., Rabier et al., 2000). In inner loops, cheaper surrogate models, e.g., the model at a lower resolution, are used, whereas the full high-resolution model is only run in a few outer loops. This could be implemented by applying our neural network surrogate in inner loops and the full neXtSIM model in outer loops.
This study only focuses on predicting the sea-ice thickness, an important variable, especially in operating forecast. However, other variables, like the sea-ice velocity components, as prognostic variables, could be predicted at the same time. Using the interactions between different variables can provide valuable information to the surrogate model. Hence, learning to emulate these variables has the potential to improve the prediction of the sea-ice thickness. Nevertheless, multivariate modeling is a more complex objective for the neural network than univariate modeling. However, a successful multivariate surrogate model might offer new perspectives for multivariate variational data assimilation.
6.6 Influence of the forcing fields
In this study, we use ERA5 reanalysis forcings, the same forcing product that has forced neXtSIM in our used simulations. Preliminary results of running the surrogate model with forcings derived from CMIP6 model output show that the surrogate can be run with other forcings (Fig. D5). Since these forcing data are based on a free-running simulation, this results in a different evolution of the sea-ice thickness than with the ERA5 reanalysis product. However, the model is stable even for other types of forcing. Therefore, the surrogate model has learned to represent the large-scale sea-ice dynamics needed to simulate the sea-ice thickness on daily and seasonal timescales.
A neural network can emulate the sea-ice thickness at a resolution of 10 km as simulated by neXtSIM. Trained for prediction of a 12 h lead time, the neural network can be iteratively applied for surrogate modeling to forecast the thickness for up to 1 year. The advantage of the surrogate model over a persistence forecast prevails from the daily timescales, with improvements of around 36 %, to seasonal timescales with more than 50 % improvement.
We introduce a regularization method for the training of the neural network, constraining the deviations of the global averaged sea-ice thickness from the targeted simulations. This regularization reduces the bias of the neural network and increases the global consistency. The increased consistency then results in a decreased forecast error on daily to weekly timescales.
By adding atmospheric forcings, the surrogate model can represent advective and thermodynamical processes that influence the sea-ice thickness on a large, Arctic-wide, scale. Hence, the seasonal predictions with the surrogate have a predictability of up to 8 months, measured by comparison to the daily climatology.
When the surrogate model is iterated, it exhibits diffusive processes, which lead to a smoothing of the prediction. The predictions are smoothed during the first iterations, as shown by a power spectral density analysis. While the smoothing induces a loss of fine-scale features, it allows the model to stay coherent for the large-scale dynamics that impact the sea-ice thickness. Thanks to this coherency, the surrogate model correctly manages to estimate the global amount of sea ice over the entire Arctic. Consequently, the surrogate model can offer a stable low-resolution adjoint for the sea-ice thickness in neXtSIM that is for example useable in a variational data assimilation framework.
The surrogate model can make 1-year long forecasts within 1 min. Therefore, the surrogate model presents itself as an opportunity to estimate a large ensemble of simulations. Such a large ensemble can enable the assimilation of previously unused observations into the sea-ice thickness.
In this Appendix, we describe more precisely the configuration of neXtSIM used. The model relies for its rheology on the brittle Bingham–Maxwell rheology (Ólason et al., 2022), which is an improvement on the Maxwell elasto-brittle (MEB) rheology (Dansereau et al., 2016). The model equations are solved on an adaptive Lagrangian triangular mesh (Rampal et al., 2016) using a finite-element method with a re-meshing protocol. This method helps preserve the gradients in the sea-ice fields which can come from the formations of leads and ridges. The main parameters used for the model are presented in Table A1. neXtSIM in this case is coupled with an ocean model (NEMO).
Table A1The main neXtSIM parameters: see Boutin et al. (2023) for more details about the model coupling.

In order to build an accuracy metric to evaluate the ability of the surrogate to predict the sea-ice thickness, it is necessary to define a threshold value to differentiate non-sea-ice grid points from sea-ice grid points. Sea-ice experts commonly define the MIZ as having a sea-ice concentration between 0.15 and 0.8 (Strong, 2012; Comiso, 2006; Rolph et al., 2020). In 1 month of neXtSIM output (124 snapshots), we compute the grid points included in this MIZ definition, and then we compute the cumulative distribution of SIT on those grid points: see Fig. B1. We select a value of σacc=0.1 for the threshold on SIT to define the sea-ice extent. If the grid point has a SIT above σacc, it is considered a sea-ice pixel; otherwise, it is considered either open sea or land.
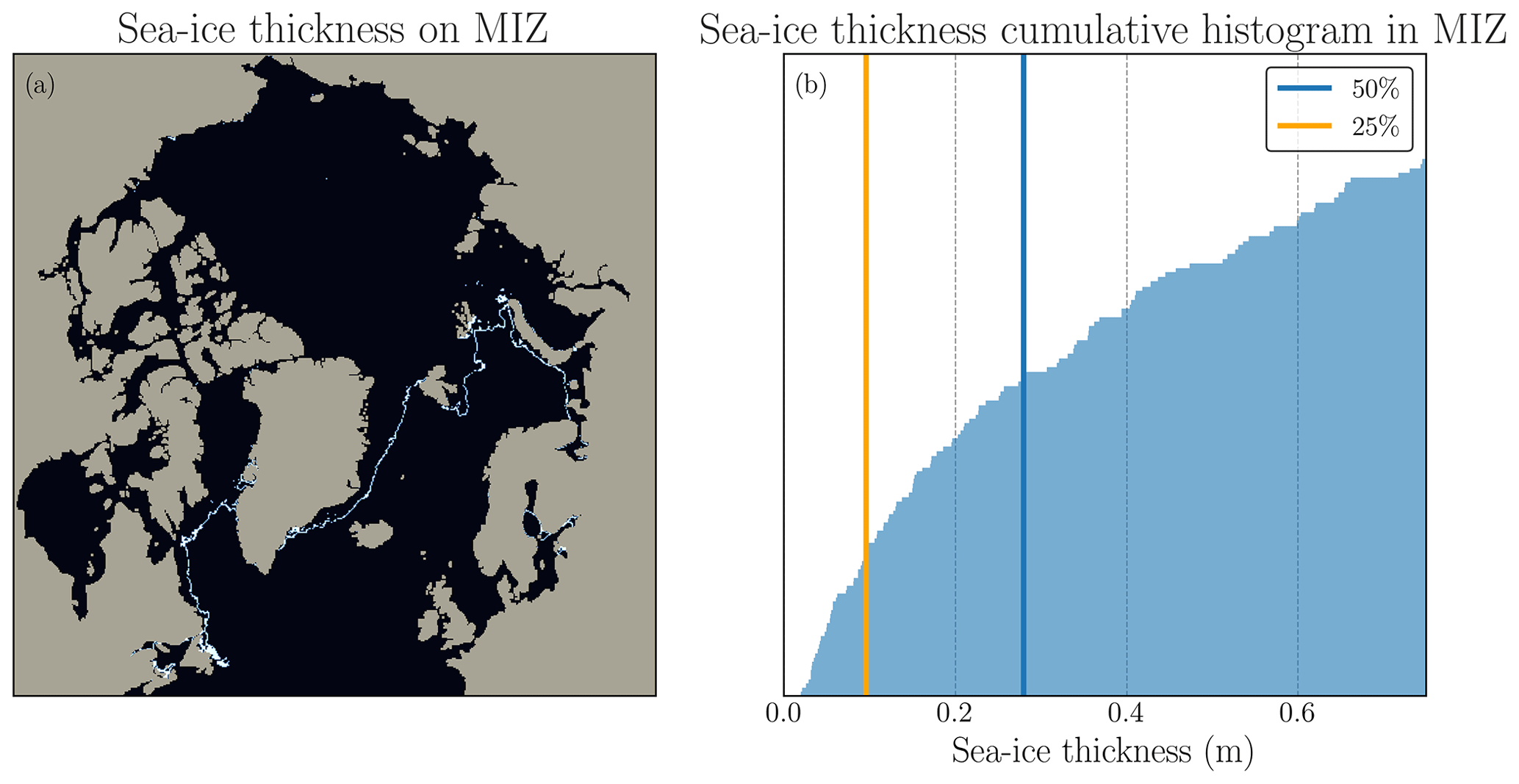
Figure B1Choice of SIT thickness threshold. In the left panel is shown the SIT thickness on the MIZ commonly defined with SIC. In the right panel is shown the cumulative distribution of this MIZ SIT. The blue vertical line outlines the mean of this distribution and the red line the 25th percentile which coincides with our chosen threshold for the SIT to define the SIE.
We detail in this section the structure of the neural networks used in the paper. The models are implemented using Tensorflow and Keras. The next sections describe the implementation of partial convolution and the detailed structure of the U-Net neural network.
C1 Partial-convolution algorithm
Instead of the Y. Liu et al. (2021) and Kadow et al. (2020) implementation of the partial convolution where the masks are convoluted alongside the images, we want to keep the mask constant only to represent the land around the sea ice. Let us define M as the mask for which 0 means a land pixel and 1 a valid pixel representing either ice or sea. Our implementation of partial convolution is reported in Algorithm C1.
Algorithm C1Partial-convolution pseudo code: it takes as input a tensor of size , with nb the batch size, nx and ny the image size, and nc the number of channels. It also requires a mask M of size (nx,ny), the kernel size of the convolution ks, an ϵ hereafter set to 10−8, and an activation function σ.
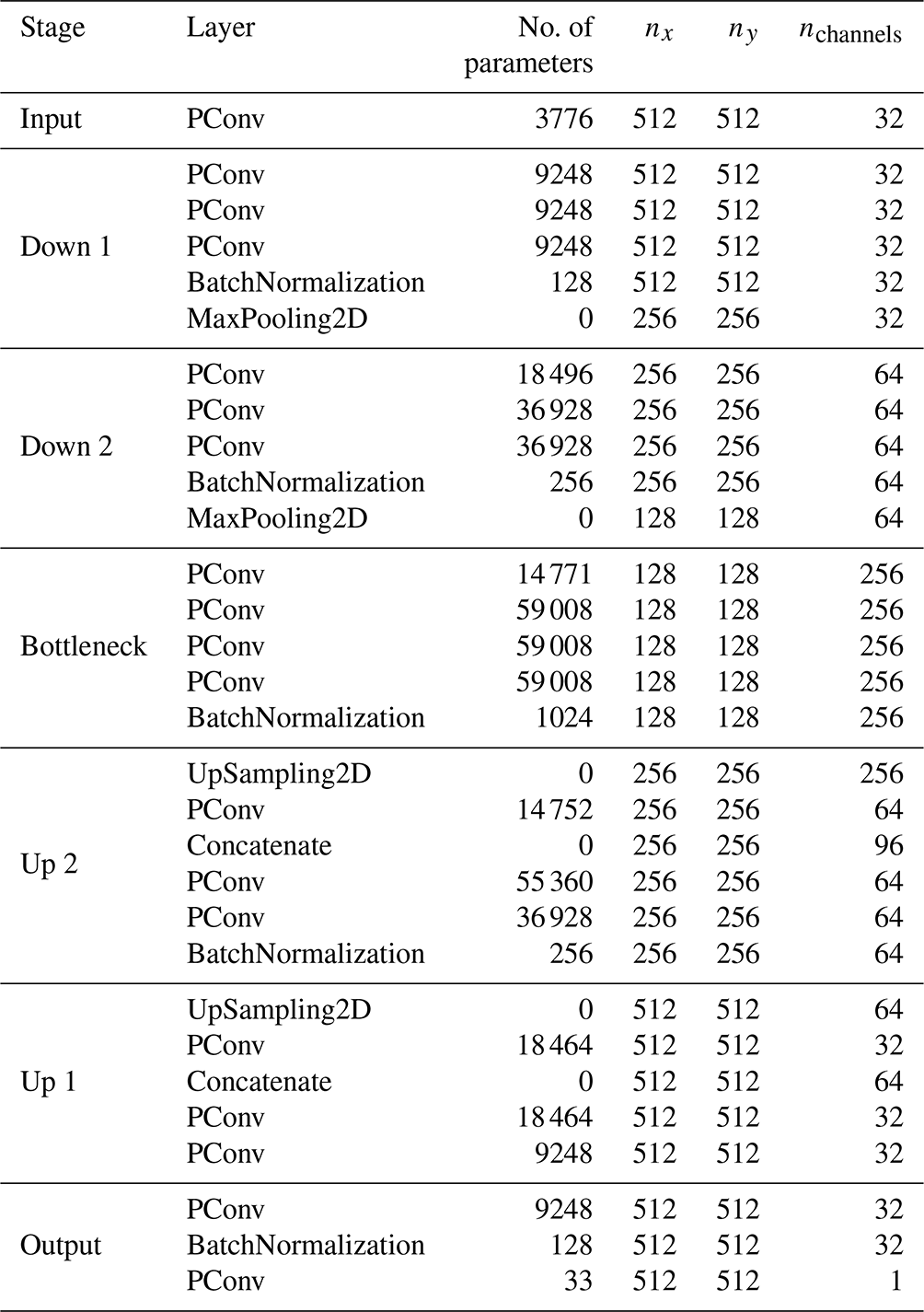
C2 U-Net
The detailed structure of the neural network is described in Table C1. It has three levels of depth, which means that the fields are coarse-grained down to (128×128) pixels and a total number of 2.4×106 parameters.
C3 Neural network training
C3.1 Losses during training
The losses as described in Sect. 3 are shown in Fig. C1 for the neural network with one input. The validation losses are plotted in transparency for each associated training loss. We do not observe overfitting, which validates the size of the U-Net with regard to the size of the dataset. The training of one U-Net takes 18 h on a single Nvidia A100 GPU.
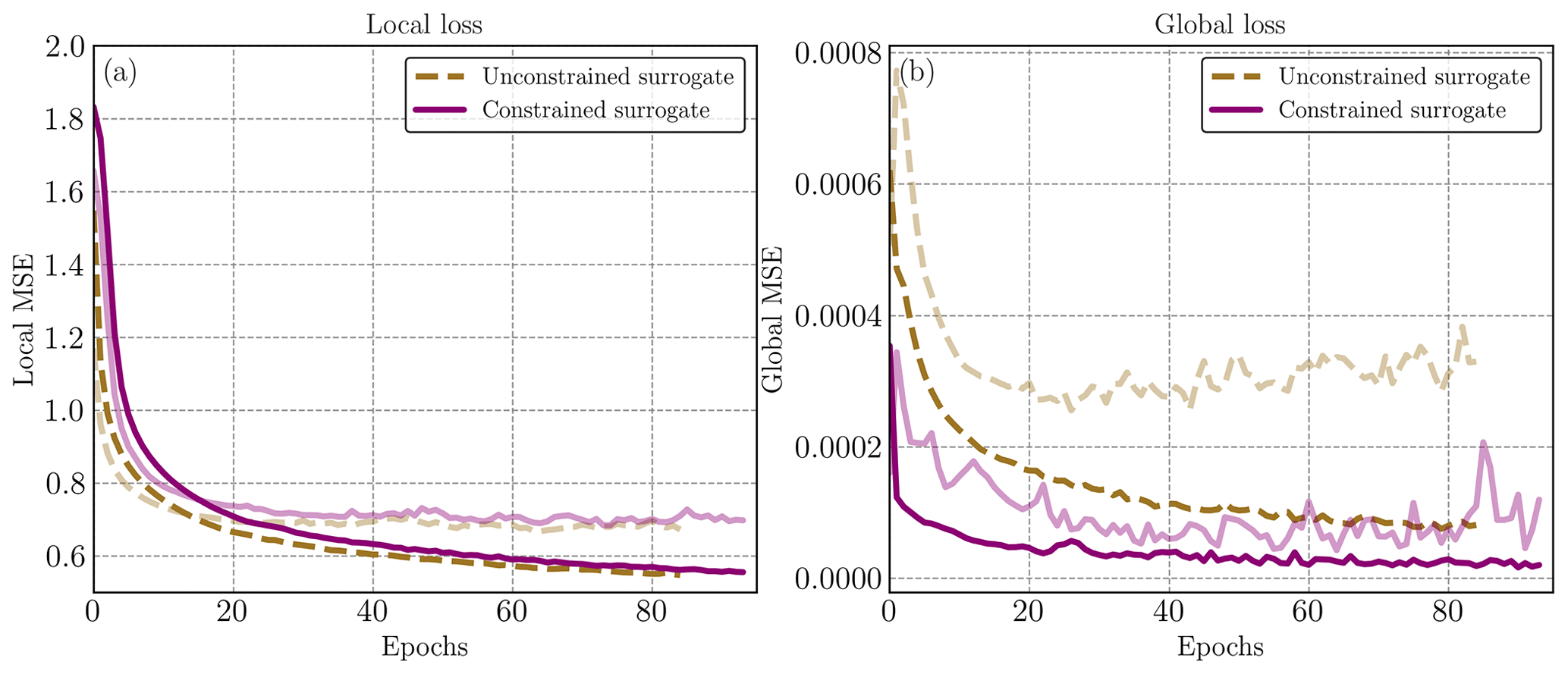
Figure C1Training and validation (in transparency) losses for the neural networks with one time step in the input. Yellow line represents the unconstrained neural network and purple the constrained neural network. We observe that adding the global term in the loss during training allows an important decrease in the global RMSE.
C3.2 Tuning of λ
In this section, we describe how the value for λ was selected. The value was chosen out of several experiments for different values of λ: 1, 10, 100, and 1000. After training the surrogate models with those values of λ, an evaluation based on the bias and the forecast skill (see Sect. 4.2) was done on the validation dataset. The impact of λ on the forecast skill was negligible and was important for the bias. Selecting a value for λ that is excessively large could result in a loss of information at the fine scale. A value of λ=100 seems to keep a good balance between fine-scale dynamics and global sea-ice thickness.
In this section, we present more snapshots of the surrogate model predictions and results with different types of forcings and resolutions.
D1 Impact of the resolution
While we observe some smoothing, we wonder about the gain in training a surrogate model on such a high-resolution model output from neXtSIM since the fine-scale dynamics in the data are smoothed by the surrogate model. Experiments were conducted on a smaller-resolution grid by coarse-graining the original dataset down to 128×128 pixels. The surrogate model is trained on this coarse dataset with the exact same method as previously described. The RMSEs from several resolutions are plotted in Fig. D1. This shows a systematic improvement over all the resolutions of the surrogate model trained on the high resolution compared to the coarse surrogate model, for different lead times.
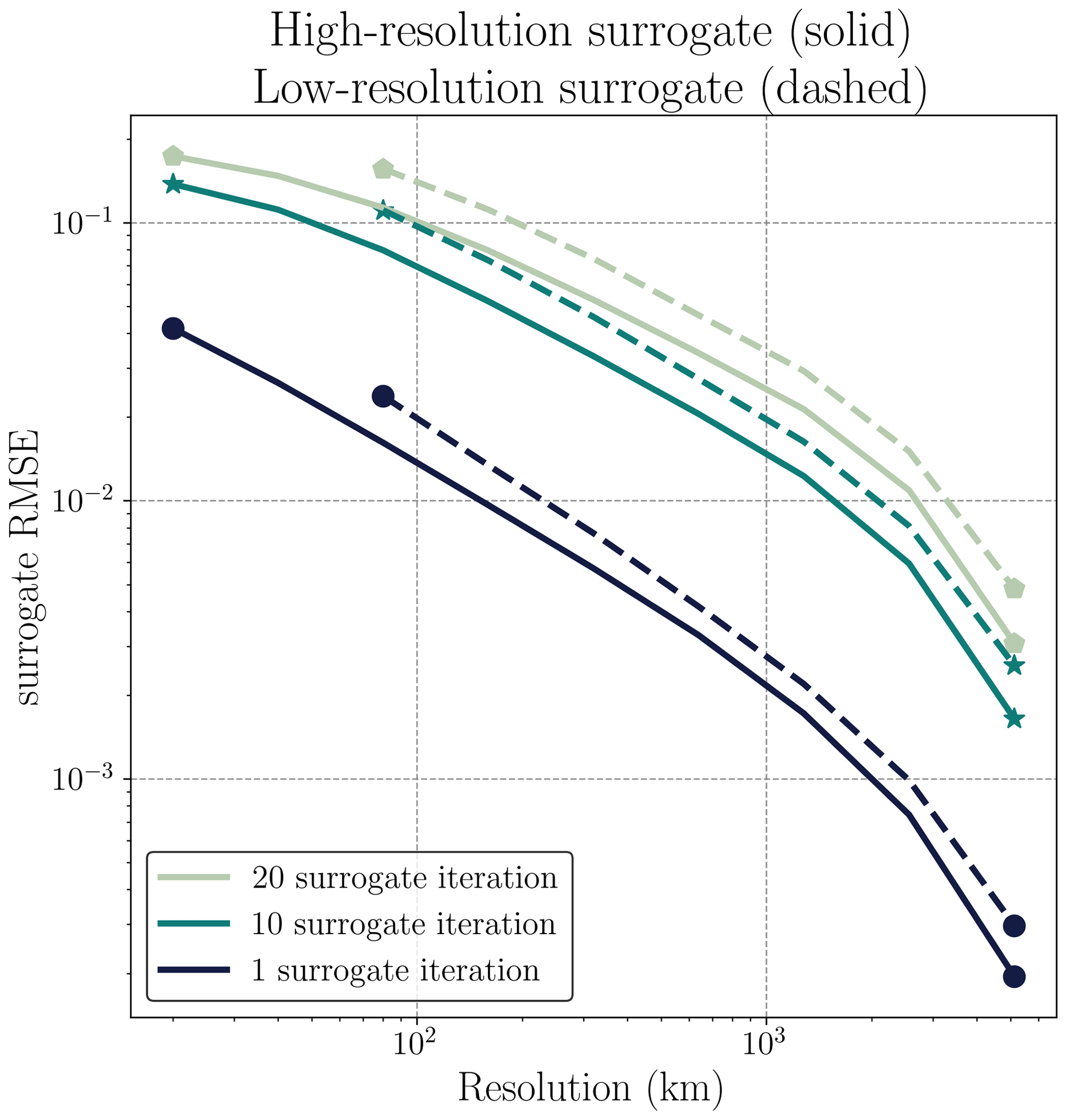
Figure D1Evaluation of the surrogate model RMSE at various resolutions. Two surrogate models trained at high resolution (solid line) and coarse-grained resolution (dashed line) are assessed in terms of RMSE, in comparison to neXtSIM, and at different scales and lead times: after 1 iteration (round markers), after 10 iterations (star markers), and after 20 iterations (hexagonal markers).
D2 Short-term forecast
In Figs. D2 and D3 we display several snapshots obtained from the constrained surrogate model alongside its corresponding neXtSIM state.
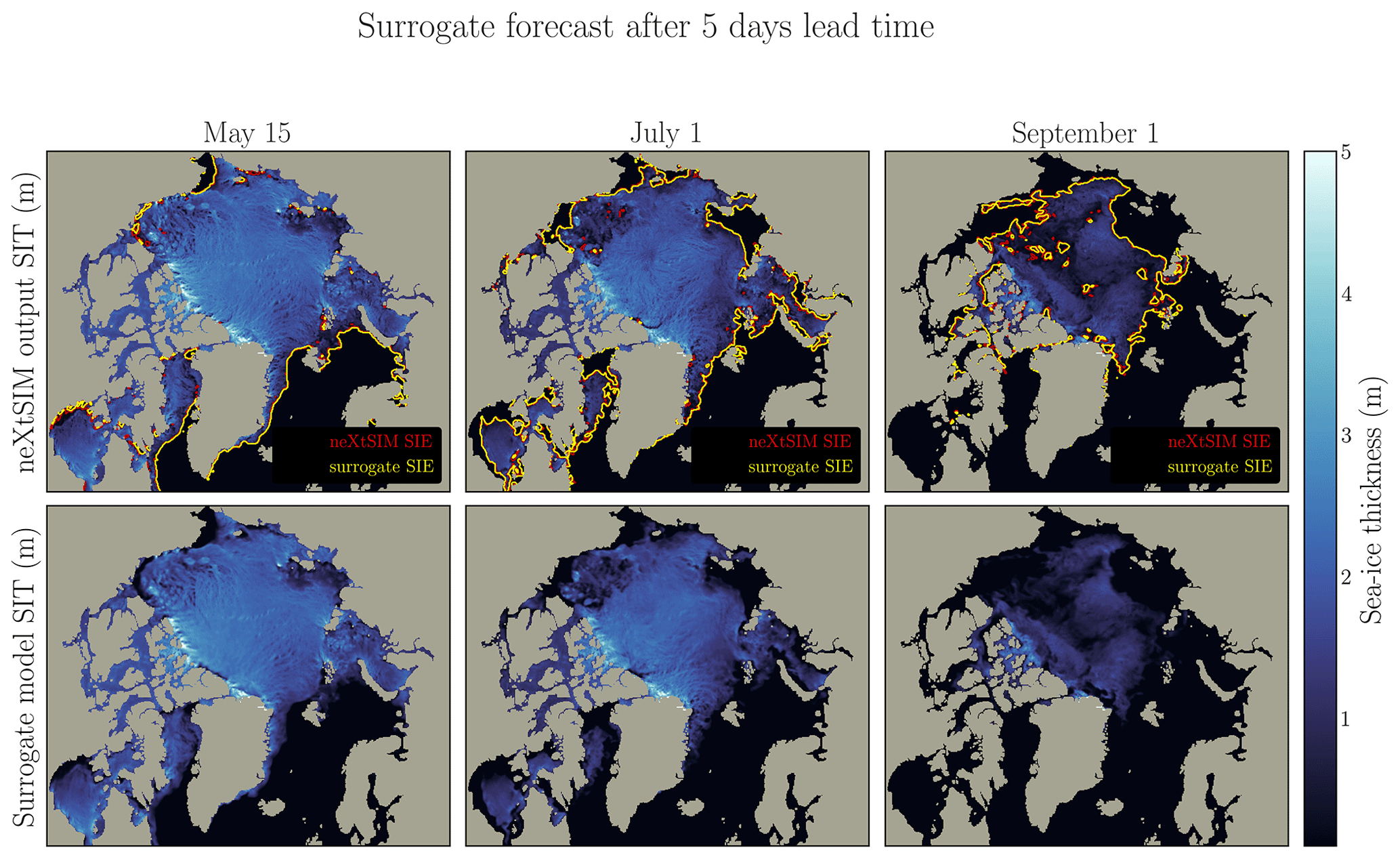
Figure D2The figure presents the surrogate model using three different initialization states (15 May, 1 July, and 1 September). The surrogate model, with constrained inputs and one-time-step configuration, is run for 5 lead days. The top panel illustrates the neXtSIM output, while the middle panel showcases the surrogate model output. Contour lines representing the sea-ice extent are displayed in the neXtSIM panel for both neXtSIM (red) and the surrogate (yellow), while the surrogate model examples omit these contours for clarity.
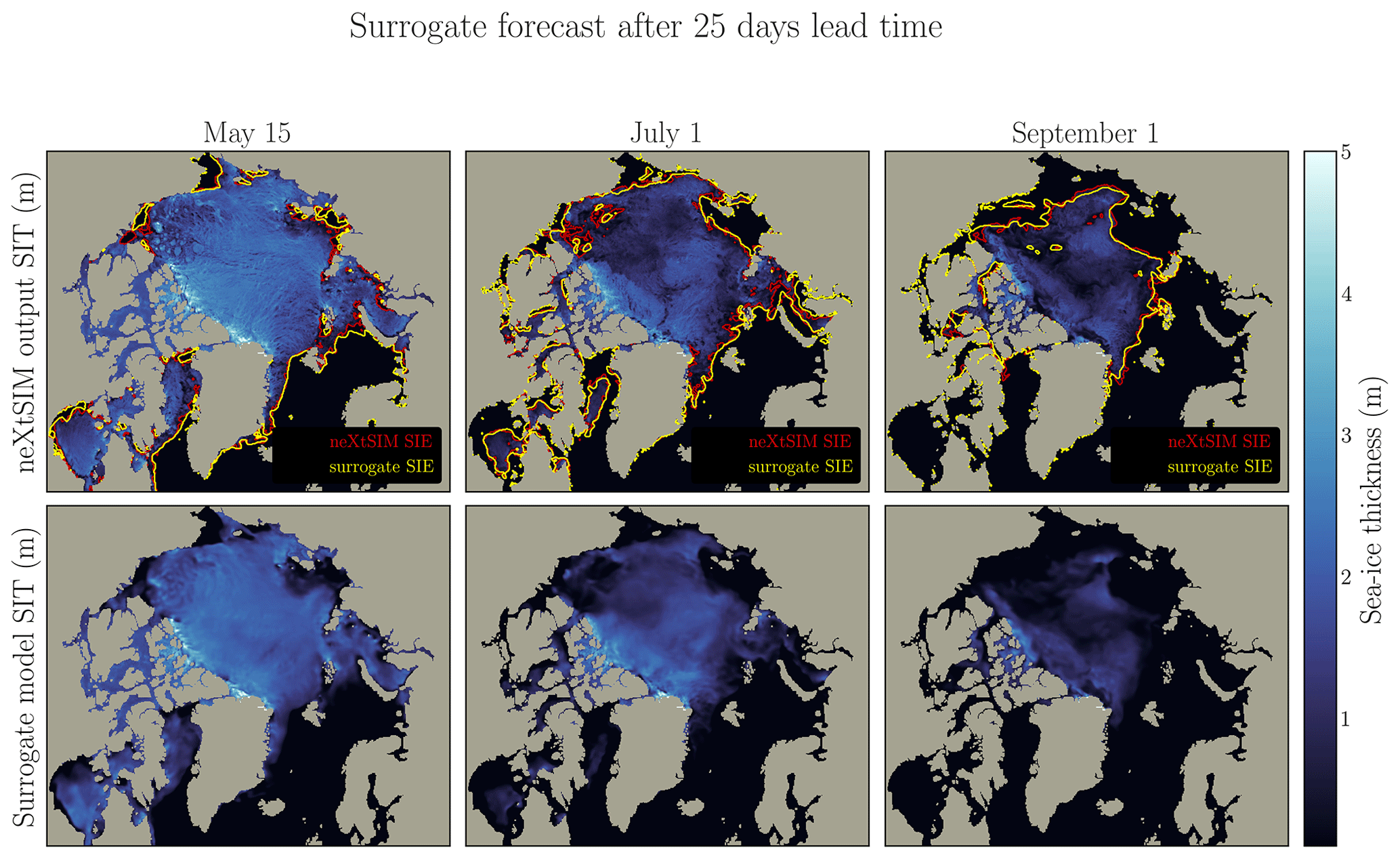
Figure D3The figure presents the surrogate model using three different initialization states (15 May, 1 July, and 1 September). The surrogate model, with constrained inputs and one-time-step configuration, is run for 25 lead days. The top panel illustrates the neXtSIM output, while the middle panel showcases the surrogate model output. Contour lines representing the sea-ice extent are displayed in the neXtSIM panel for both neXtSIM (red) and the surrogate (yellow), while the surrogate model examples omit these contours for clarity.
D3 Seasonal forecast
In Fig. D4 we can observe several snapshots obtained from the stable constrained surrogate model alongside its corresponding neXtSIM state. For every time step shown, the surrogate model correctly manages to estimate the global state of the system. However, the smooth advection appears at the leading process. It is nonetheless a good approximation of the sea-ice structure during the full year.

Figure D4Snapshots for seasonal forecast of neXtSIM and the surrogate. The surrogate model is run starting from 1 January 2006 for 720 iterations. Results after 100, 300, and 600 iterations are presented in this figure. Results are plotted with the neXtSIM output above and the surrogate model in the middle panel. In the neXtSIM panel are plotted the contour of the sea-ice extent for both neXtSIM (red) and the surrogate (yellow). For better clarity, those contours are not represented in the surrogate model examples.
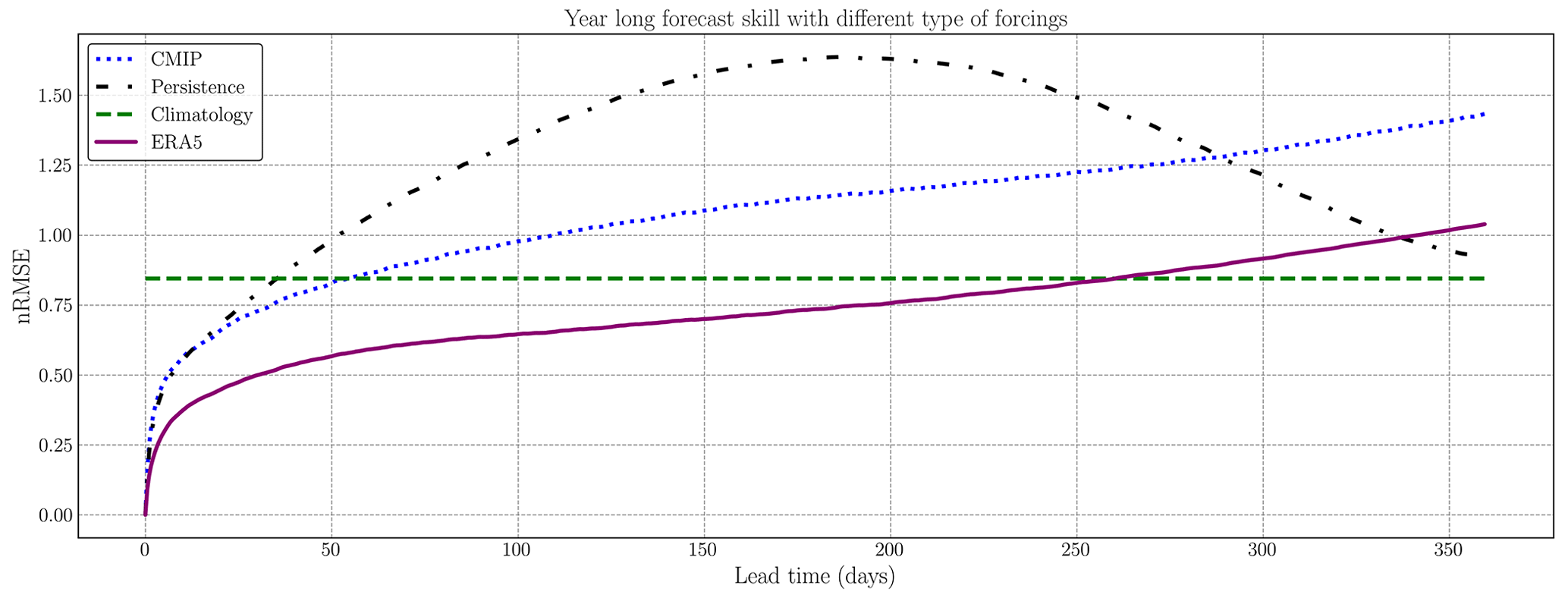
Figure D5Seasonal forecast of the surrogate model while changing the type of forcing in 2018. The neural network remains exactly the same as the trained one. It is thus trained with ERA5 forcings. In the test part, the forcings are changed to CMIP6 forcings (blue dotted line). This forecast skill is compared with neXtSIM and ERA5 forcings (purple solid line), persistence (black dashed line) and daily climatology (green dashed line).
D4 CMIP forcings
As explained in Sect. 6, we evaluate our surrogate model approach with another type of forcing. The forcings are taken from the ECMWF-IFS-HR (25 km atmosphere and 25 km ocean) climate model (Roberts et al., 2017). The surface temperature and velocities are taken, projected onto the neXtSIM grid and normalized to be able to be fit into the input of the surrogate model. The results are presented in Fig. D5. We see that there is after 50 d a constant bias difference between the surrogate with the different forcings, with the same global behavior. The surrogate model with CMIP6 forcings correctly handles the decrease in the SIE during September, but it has difficulties in matching neXtSIM during the next refreezing period. We hypothesize that this is caused by the important bias difference between the forcings, neXtSIM being simulated with ERA5 forcings. In any case, our surrogate model remains stable when changing the forcings.
D5 Quantification of diffusion
In this section, we describe how the spectral exponent of the power law is computed, following Clauset et al. (2009). After normalizing the data coming from Eq. (15), with Simpson's rule, we fit the distribution with a function of the form
for x>xmin, which is manually chosen. The log-likelihood function becomes
with representing the n points above xmin. By differentiating this likelihood with respect to β and setting the result to 0, we obtain its maximum, which yields the estimator equation:
The computation of the spectral exponent is performed using this technique across all samples of the test dataset and all lead times, under the same restrictions. We exclude the first 10 points and the last 20 points of the distribution to focus on the linear part of the PSD. Indeed, as depicted in Fig. 8b, after some time, a flattening of the PSD is observed on the fine scale directly linked to the smoothing of the emulated sea-ice thickness.
The source code to build the dataset, train the neural networks and plot the figures is publicly available at https://doi.org/10.5281/zenodo.10784995 (Durand, 2024). neXtSIM simulation outputs can be found at https://github.com/sasip-climate/catalog-shared-data-SASIP following Boutin et al. (2022) (https://doi.org/10.5281/zenodo.7277523) and the associated code therein. Additional atmospheric forcings can be downloaded at https://doi.org/10.24381/cds.adbb2d47 (Hersbach et al., 2023).
A video of the seasonal forecast for the year 2017 is available at https://doi.org/10.5446/62131 (Durand, 2023).
EÓ provided the data and the insights into neXtSIM. GB ran the simulation of neXtSIM and built the SIT dataset. CD, TSF, AF, and MB refined the scientific questions and prepared an analysis strategy. CD performed the experiments. CD, TSF, AF, and MB analyzed and discussed the results. CD wrote the manuscript with TSF, AF, MB, and GB and with EÓ reviewing.
The authors declare that they have no conflict of interest.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors.
The authors acknowledge the support of project SASIP (grant no. 353) funded by Schmidt Futures – a philanthropic initiative that seeks to improve societal outcomes through the development of emerging science and technologies. This work was granted access to the HPC resources of IDRIS under the allocations 2021-AD011013069 and 2022-AD011013069R1 made by GENCI. The authors would like to thank Pierre Rampal, Laurent Bertino, Anton Korosov, Julien Brajard and their colleagues from NERSC for their insightful inputs. The authors would also like to thank two reviewers, Nils Hutter and Sahara Ali, for their comments and remarks that helped improve the manuscript. CEREA is a member of the Institut Pierre-Simon Laplace (IPSL).
This research has been supported by the Schmidt Family Foundation (grant no. 353) and the Grand Équipement National de Calcul Intensif (grant nos. 2021-AD011013069 and 2022-AD011013069R1).
This paper was edited by Patricia de Rosnay and reviewed by Sahara Ali and Nils Hutter.
Amodei, M. and Stein, J.: Deterministic and fuzzy verification methods for a hierarchy of numerical models, Meteorol. Appl., 16, 191–203, https://doi.org/10.1002/met.101, 2009. a
Andersson, T. R., Hosking, J. S., Pérez-Ortiz, M., Paige, B., Elliott, A., Russell, C., Law, S., Jones, D. C., Wilkinson, J., Phillips, T., Byrne, J., Tietsche, S., Sarojini, B. B., Blanchard-Wrigglesworth, E., Aksenov, Y., Downie, R., and Shuckburgh, E.: Seasonal Arctic sea ice forecasting with probabilistic deep learning, Nat. Commun., 12, 5124, https://doi.org/10.1038/s41467-021-25257-4, 2021. a
Balan-Sarojini, B., Tietsche, S., Mayer, M., Balmaseda, M., Zuo, H., de Rosnay, P., Stockdale, T., and Vitart, F.: Year-round impact of winter sea ice thickness observations on seasonal forecasts, The Cryosphere, 15, 325–344, https://doi.org/10.5194/tc-15-325-2021, 2021. a
Bernard, B., Madec, G., Penduff, T., Molines, J.-M., Treguier, A.-M., Sommer, J. L., Beckmann, A., Biastoch, A., Böning, C., Dengg, J., Derval, C., Durand, E., Gulev, S., Remy, E., Talandier, C., Theetten, S., Maltrud, M., McClean, J., and Cuevas, B. D.: Impact of partial steps and momentum advection schemes in a global ocean circulation model at eddy-permitting resolution, Ocean Dynam., 56, 543–567, https://doi.org/10.1007/s10236-006-0082-1, 2006. a
Beucler, T., Pritchard, M., Rasp, S., Ott, J., Baldi, P., and Gentine, P.: Enforcing Analytic Constraints in Neural Networks Emulating Physical Systems, Phys. Rev. Lett., 126, 098302, https://doi.org/10.1103/physrevlett.126.098302, 2021. a
Bi, K., Xie, L., Zhang, H., Chen, X., Gu, X., and Tian, Q.: Pangu-Weather: A 3D High-Resolution Model for Fast and Accurate Global Weather Forecast, ArXiv, https://doi.org/10.48550/ARXIV.2211.02556, 2022. a
Blanchard-Wrigglesworth, E., Armour, K. C., Bitz, C. M., and DeWeaver, E.: Persistence and Inherent Predictability of Arctic Sea Ice in a GCM Ensemble and Observations, J. Climate, 24, 231–250, https://doi.org/10.1175/2010jcli3775.1, 2011. a
Bochkovskiy, A., Wang, C.-Y., and Liao, H.-Y. M.: YOLOv4: Optimal Speed and Accuracy of Object Detection, ArXiv, https://doi.org/10.48550/ARXIV.2004.10934, 2020. a
Bocquet, M.: Surrogate modelling for the climate sciences dynamics with machine learning and data assimilation, Front. Appl. Math. Stat., 9, 1133226, https://doi.org/10.3389/fams.2023.1133226, 2023. a
Bouchat, A., Hutter, N., Chanut, J., Dupont, F., Dukhovskoy, D., Garric, G., Lee, Y. J., Lemieux, J.-F., Lique, C., Losch, M., Maslowski, W., Myers, P. G., Ólason, E., Rampal, P., Rasmussen, T., Talandier, C., Tremblay, B., and Wang, Q.: Sea Ice Rheology Experiment (SIREx): 1. Scaling and Statistical Properties of Sea-Ice Deformation Fields, J. Geophys. Res.-Oceans, 127, e2021JC017667, https://doi.org/10.1029/2021JC017667, 2022. a, b
Boutin, G., Regan, H., Ólason, E., Brodeau, L., Talandier, C., Lique, C., and Rampal, P.: Data accompanying the article “Arctic sea ice mass balance in a new coupled ice-ocean model using a brittle rheology framework” (1.0), Zenodo [data set], https://doi.org/10.5281/zenodo.7277523, 2022. a
Boutin, G., Ólason, E., Rampal, P., Regan, H., Lique, C., Talandier, C., Brodeau, L., and Ricker, R.: Arctic sea ice mass balance in a new coupled ice–ocean model using a brittle rheology framework, The Cryosphere, 17, 617–638, https://doi.org/10.5194/tc-17-617-2023, 2023. a, b, c, d
Cheng, S. B., Quilodrán-Casas, C., Ouala, S., Farchi, A., Liu, C., Tandeo, P., Fablet, R., Lucor, D., Iooss, B., Brajard, J., Xiao, D. H., Janjic, T., Ding, W. P., Guo, Y. K., Carrassi, A., Bocquet, M., and Arcucci, R.: Machine learning with data assimilation and uncertainty quantification for dynamical systems: A review, IEEE/CAA J. Autom. Sinica, 10, 1361–1387, https://doi.org/10.1109/JAS.2023.123537, 2023. a
Clauset, A., Shalizi, C. R., and Newman, M. E. J.: Power-Law Distributions in Empirical Data, SIAM Review, 51, 661–703, https://doi.org/10.1137/070710111, 2009. a
Comiso, J. C.: Abrupt decline in the Arctic winter sea ice cover, Geophys. Res. Lett., 33, L18504, https://doi.org/10.1029/2006gl027341, 2006. a
Dansereau, V., Weiss, J., Saramito, P., and Lattes, P.: A Maxwell elasto-brittle rheology for sea ice modelling, The Cryosphere, 10, 1339–1359, https://doi.org/10.5194/tc-10-1339-2016, 2016. a, b
Durand, C.: Seasonal forecast of surrogate modeling of neXtSIM, Copernicus Publications [video], https://doi.org/10.5446/62131, 2023. a
Durand, C.: Code for “Data-driven surrogate modeling of high-resolution sea-ice thickness in the Arctic” published in The Cryosphere (Version v1), Zenodo [code], https://doi.org/10.5281/zenodo.10784995, 2024. a
Farchi, A., Bocquet, M., Roustan, Y., Mathieu, A., and Quérel, A.: Using the Wasserstein distance to compare fields of pollutants: application to the radionuclide atmospheric dispersion of the Fukushima-Daiichi accident, Tellus B, 68, 31682, https://doi.org/10.3402/tellusb.v68.31682, 2016. a
Finn, T. S., Disson, L., Farchi, A., Bocquet, M., and Durand, C.: Representation learning with unconditional denoising diffusion models for dynamical systems, EGUsphere [preprint], https://doi.org/10.5194/egusphere-2023-2261, 2023a. a
Finn, T. S., Durand, C., Farchi, A., Bocquet, M., Chen, Y., Carrassi, A., and Dansereau, V.: Deep learning subgrid-scale parametrisations for short-term forecasting of sea-ice dynamics with a Maxwell elasto-brittle rheology, The Cryosphere, 17, 2965–2991, https://doi.org/10.5194/tc-17-2965-2023, 2023b. a
Girard, L., Bouillon, S., Weiss, J., Amitrano, D., Fichefet, T., and Legat, V.: A new modeling framework for sea-ice mechanics based on elasto-brittle rheology, Ann. Glaciol., 52, 123–132, https://doi.org/10.3189/172756411795931499, 2011. a
Goessling, H. F., Tietsche, S., Day, J. J., Hawkins, E., and Jung, T.: Predictability of the Arctic sea ice edge, Geophys. Res. Lett., 43, 1642–1650, https://doi.org/10.1002/2015gl067232, 2016. a
Grigoryev, T., Verezemskaya, P., Krinitskiy, M., Anikin, N., Gavrikov, A., Trofimov, I., Balabin, N., Shpilman, A., Eremchenko, A., Gulev, S., Burnaev, E., and Vanovskiy, V.: Data-Driven Short-Term Daily Operational Sea Ice Regional Forecasting, Remote Sens., 14, 5837, https://doi.org/10.3390/rs14225837, 2022. a
Guemas, V., Blanchard-Wrigglesworth, E., Chevallier, M., Day, J. J., Déqué, M., Doblas-Reyes, F. J., Fučkar, N. S., Germe, A., Hawkins, E., Keeley, S., Koenigk, T., y Mélia, D. S., and Tietsche, S.: A review on Arctic sea-ice predictability and prediction on seasonal to decadal time-scales, Q. J. Roy. Meteor. Soc., 142, 546–561, https://doi.org/10.1002/qj.2401, 2014. a
He, K., Zhang, X., Ren, S., and Sun, J.: Deep Residual Learning for Image Recognition, 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 770–778, https://doi.org/10.1109/CVPR.2016.90, 2016. a
Hersbach, H., Bell, B., Berrisford, P., Hirahara, S., Horányi, A., Muñoz-Sabater, J., Nicolas, J., Peubey, C., Radu, R., Schepers, D., Simmons, A., Soci, C., Abdalla, S., Abellan, X., Balsamo, G., Bechtold, P., Biavati, G., Bidlot, J., Bonavita, M., Chiara, G., Dahlgren, P., Dee, D., Diamantakis, M., Dragani, R., Flemming, J., Forbes, R., Fuentes, M., Geer, A., Haimberger, L., Healy, S., Hogan, R. J., Hólm, E., Janisková, M., Keeley, S., Laloyaux, P., Lopez, P., Lupu, C., Radnoti, G., Rosnay, P., Rozum, I., Vamborg, F., Villaume, S., and Thépaut, J.-N.: The ERA5 global reanalysis, Q. J. Roy. Meteor. Soc., 146, 1999–2049, https://doi.org/10.1002/qj.3803, 2020. a
Hersbach, H., Bell, B., Berrisford, P., Biavati, G., Horányi, A., Muñoz Sabater, J., Nicolas, J., Peubey, C., Radu, R., Rozum, I., Schepers, D., Simmons, A., Soci, C., Dee, D., and Thépaut, J.-N.: ERA5 hourly data on single levels from 1940 to present, Copernicus Climate Change Service (C3S) Climate Data Store (CDS) [data set], https://doi.org/10.24381/cds.adbb2d47 (last access: 10 February 2023), 2023. a
Hess, P., Lange, S., and Boers, N.: Deep Learning for bias-correcting comprehensive high-resolution Earth system models, ArXiv, https://doi.org/10.48550/ARXIV.2301.01253, 2023. a
Horvat, C. and Roach, L. A.: WIFF1.0: a hybrid machine-learning-based parameterization of wave-induced sea ice floe fracture, Geosci. Model Dev., 15, 803–814, https://doi.org/10.5194/gmd-15-803-2022, 2022. a
Hunke, E., Lipscomb, W., Jones, P., Turner, A., Jeffery, N., and Elliott, S.: CICE, the Los Alamos sea ice model, Tech. rep., Los Alamos National Lab.(LANL), Los Alamos, NM (United States), 2017. a
Kadow, C., Hall, D. M., and Ulbrich, U.: Artificial intelligence reconstructs missing climate information, Nat. Geosci., 13, 408–413, https://doi.org/10.1038/s41561-020-0582-5, 2020. a, b
Keisler, R.: Forecasting Global Weather with Graph Neural Networks, ArXiv, https://doi.org/10.48550/ARXIV.2202.07575, 2022. a
Kim, Y. J., Kim, H.-C., Han, D., Lee, S., and Im, J.: Prediction of monthly Arctic sea ice concentrations using satellite and reanalysis data based on convolutional neural networks, The Cryosphere, 14, 1083–1104, https://doi.org/10.5194/tc-14-1083-2020, 2020. a
Køltzow, M., Schyberg, H., Støylen, E., and Yang, X.: Value of the Copernicus Arctic Regional Reanalysis (CARRA) in representing near-surface temperature and wind speed in the north-east European Arctic, Polar Res., 41, 8002, https://doi.org/10.33265/polar.v41.8002, 2022. a
Kwok, R.: Contrasts in sea ice deformation and production in the Arctic seasonal and perennial ice zones, J. Geophys. Res., 111, C11S22, https://doi.org/10.1029/2005jc003246, 2006. a
Kwok, R., Spreen, G., and Pang, S.: Arctic sea ice circulation and drift speed: Decadal trends and ocean currents, J. Geophys. Res.-Oceans, 118, 2408–2425, https://doi.org/10.1002/jgrc.20191, 2013. a
Lam, R., Sanchez-Gonzalez, A., Willson, M., Wirnsberger, P., Fortunato, M., Pritzel, A., Ravuri, S., Ewalds, T., Alet, F., Eaton-Rosen, Z., Hu, W., Merose, A., Hoyer, S., Holland, G., Stott, J., Vinyals, O., Mohamed, S., and Battaglia, P.: GraphCast: Learning skillful medium-range global weather forecasting, ArXiv, https://doi.org/10.48550/ARXIV.2212.12794, 2022. a
Leinonen, J., Hamann, U., Nerini, D., Germann, U., and Franch, G.: Latent diffusion models for generative precipitation nowcasting with accurate uncertainty quantification, ArXiv, https://doi.org/10.48550/arXiv.2304.12891, arXiv:2304.12891 [physics], 2023. a
Lemke, P., Trinkl, E. W., and Hasselmann, K.: Stochastic Dynamic Analysis of Polar Sea Ice Variability, J. Phys. Oceanogr., 10, 2100–2120, https://doi.org/10.1175/1520-0485(1980)010<2100:sdaops>2.0.co;2, 1980. a
Liu, G., Reda, F. A., Shih, K. J., Wang, T., Tao, A., and Catanzaro, B.: Image Inpainting for Irregular Holes Using Partial Convolutions, CoRR, abs/1804.07723, http://arxiv.org/abs/1804.07723 (last access: 17 March 2023), 2018. a
Liu, Q., Zhang, R., Wang, Y., Yan, H., and Hong, M.: Daily Prediction of the Arctic Sea Ice Concentration Using Reanalysis Data Based on a Convolutional LSTM Network, J. Marine Sci. Eng., 9, 330, https://doi.org/10.3390/jmse9030330, 2021. a
Liu, Y., Bogaardt, L., Attema, J., and Hazeleger, W.: Extended Range Arctic Sea Ice Forecast with Convolutional Long-Short Term Memory Networks, Mon. Weather Rev., 149, 1673–1693, https://doi.org/10.1175/mwr-d-20-0113.1, 2021. a, b, c
Loshchilov, I. and Hutter, F.: Fixing Weight Decay Regularization in Adam, CoRR, abs/1711.05101, http://arxiv.org/abs/1711.05101 (last access: 23 March 2023), 2017. a
Lovejoy, S., Tarquis, A. M., Gaonac′h, H., and Schertzer, D.: Single- and Multiscale Remote Sensing Techniques, Multifractals, and MODIS-Derived Vegetation and Soil Moisture, Vadose Zone J., 7, 533–546, https://doi.org/10.2136/vzj2007.0173, 2008. a
Madec, G., Delecluse, P., Imbard, M., and Levy, C.: OPA 8 Ocean General Circulation Model – Reference Manual, Tech. rep., LODYC/IPSL Note 11, 1998. a
Mardani, M., Brenowitz, N., Cohen, Y., Pathak, J., Chen, C.-Y., Liu, C.-C., Vahdat, A., Kashinath, K., Kautz, J., and Pritchard, M.: Generative Residual Diffusion Modeling for Km-scale Atmospheric Downscaling, arXiv:2309.15214 [physics], https://doi.org/10.48550/arXiv.2309.15214, 2023. a
Misra, D.: Mish: A Self Regularized Non-Monotonic Neural Activation Function, CoRR, abs/1908.08681, ArXiv [preprint], http://arxiv.org/abs/1908.08681 (last access: 20 March 2023), 2019. a
Neuhauser, M., Verrier, S., and Mangiarotti, S.: Multifractal analysis for spatial characterization of high resolution Sentinel-2/MAJA products in Southwestern France, Remote Sens. Environ., 270, 112859, https://doi.org/10.1016/j.rse.2021.112859, 2022. a
Nguyen, T., Brandstetter, J., Kapoor, A., Gupta, J. K., and Grover, A.: ClimaX: A foundation model for weather and climate, ArXiv, https://doi.org/10.48550/ARXIV.2301.10343, 2023. a
Nielsen-Englyst, P., Høyer, J. L., Madsen, K. S., Tonboe, R. T., Dybkjær, G., and Skarpalezos, S.: Deriving Arctic 2 m air temperatures over snow and ice from satellite surface temperature measurements, The Cryosphere, 15, 3035–3057, https://doi.org/10.5194/tc-15-3035-2021, 2021. a
Ólason, E., Boutin, G., Korosov, A., Rampal, P., Williams, T., Kimmritz, M., Dansereau, V., and Samaké, A.: A New Brittle Rheology and Numerical Framework for Large‐Scale Sea‐Ice Models, J. Adv. Model. Earth Sy., 14, e2021MS002685, https://doi.org/10.1029/2021ms002685, 2022. a, b, c
Olonscheck, D., Mauritsen, T., and Notz, D.: Arctic sea-ice variability is primarily driven by atmospheric temperature fluctuations, Nat. Geosci., 12, 430–434, https://doi.org/10.1038/s41561-019-0363-1, 2019. a
Pinckaers, H., van Ginneken, B., and Litjens, G.: Streaming Convolutional Neural Networks for End-to-End Learning with Multi-Megapixel Images, IEEE T. Pattern Anal., 44, 1581–1590, https://doi.org/10.1109/TPAMI.2020.3019563, 2022. a
Plueddemann, A. J., Krishfield, R., Takizawa, T., Hatakeyama, K., and Honjo, S.: Upper ocean velocities in the Beaufort Gyre, Geophys. Res. Lett., 25, 183–186, https://doi.org/10.1029/97gl53638, 1998. a
Price, I., Sanchez-Gonzalez, A., Alet, F., Ewalds, T., El-Kadi, A., Stott, J., Mohamed, S., Battaglia, P., Lam, R., and Willson, M.: GenCast: Diffusion-based ensemble forecasting for medium-range weather, arXiv:2312.15796 [physics], https://doi.org/10.48550/arXiv.2312.15796, 2023. a
Rabier, F., Järvinen, H., Klinker, E., Mahfouf, J.-F., and Simmons, A.: The ECMWF operational implementation of four-dimensional variational assimilation. I: Experimental results with simplified physics, Q. J. Roy. Meteor. Soc., 126, 1143–1170, https://doi.org/10.1002/qj.49712656415, 2000. a
Rampal, P., Bouillon, S., Ólason, E., and Morlighem, M.: neXtSIM: a new Lagrangian sea ice model, The Cryosphere, 10, 1055–1073, https://doi.org/10.5194/tc-10-1055-2016, 2016. a, b, c, d
Rampal, P., Dansereau, V., Olason, E., Bouillon, S., Williams, T., Korosov, A., and Samaké, A.: On the multi-fractal scaling properties of sea ice deformation, The Cryosphere, 13, 2457–2474, https://doi.org/10.5194/tc-13-2457-2019, 2019. a, b
Ravuri, S., Lenc, K., Willson, M., Kangin, D., Lam, R., Mirowski, P., Fitzsimons, M., Athanassiadou, M., Kashem, S., Madge, S., Prudden, R., Mandhane, A., Clark, A., Brock, A., Simonyan, K., Hadsell, R., Robinson, N., Clancy, E., Arribas, A., and Mohamed, S.: Skilful precipitation nowcasting using deep generative models of radar, Nature, 597, 672–677, https://doi.org/10.1038/s41586-021-03854-z, 2021. a, b
Roberts, C. D., Senan, R., Molteni, F., Boussetta, S., and Keeley, S.: ECMWF ECMWF-IFS-HR model output prepared for CMIP6 HighResMIP control-1950, Version 20230506, ECRP [data set], https://doi.org/10.22033/ESGF/CMIP6.4945, 2017. a
Rolph, R. J., Feltham, D. L., and Schröder, D.: Changes of the Arctic marginal ice zone during the satellite era, The Cryosphere, 14, 1971–1984, https://doi.org/10.5194/tc-14-1971-2020, 2020. a
Ronneberger, O., Fischer, P., and Brox, T.: U-Net: Convolutional Networks for Biomedical Image Segmentation, CoRR, ArXiv, abs/1505.04597, http://arxiv.org/abs/1505.04597 (last access: 20 March 2023), 2015. a
Rousset, C., Vancoppenolle, M., Madec, G., Fichefet, T., Flavoni, S., Barthélemy, A., Benshila, R., Chanut, J., Levy, C., Masson, S., and Vivier, F.: The Louvain-La-Neuve sea ice model LIM3.6: global and regional capabilities, Geosci. Model Dev., 8, 2991–3005, https://doi.org/10.5194/gmd-8-2991-2015, 2015. a
Serreze, M. C., Barry, R. G., and McLaren, A. S.: Seasonal variations in sea ice motion and effects on sea ice concentration in the Canada Basin, J. Geophys. Res.-Oceans, 94, 10955–10970, https://doi.org/10.1029/jc094ic08p10955, 1989. a
Serreze, M. C., Maslanik, J. A., Barry, R. G., and Demaria, T. L.: Winter atmospheric circulation in the Arctic Basin and possible relationships to the great salinity anomaly in the northern North Atlantic, Geophys. Res. Lett., 19, 293–296, https://doi.org/10.1029/91gl02946, 1992. a
Shi, X., Chen, Z., Wang, H., Yeung, D.-Y., Wong, W.-k., and Woo, W.-c.: Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting, in: Advances in Neural Information Processing Systems, vol. 28, Curran Associates, Inc., https://proceedings.neurips.cc/paper_files/paper/2015/hash/07563a3fe3bbe7e3ba84431ad9d055af-Abstract.html (last access: 25 March 2023), 2015. a
Sievers, I., Gierisch, A. M. U., Rasmussen, T. A. S., Hordoir, R., and Stenseng, L.: Arctic sea ice and snow from different ice models: A CICE–SI3 intercomparison study, The Cryosphere Discuss. [preprint], https://doi.org/10.5194/tc-2022-84, 2022. a
Sigmond, M., Fyfe, J. C., Flato, G. M., Kharin, V. V., and Merryfield, W. J.: Seasonal forecast skill of Arctic sea ice area in a dynamical forecast system, Geophys. Res. Lett., 40, 529–534, https://doi.org/10.1002/grl.50129, 2013. a
Strong, C.: Atmospheric influence on Arctic marginal ice zone position and width in the Atlantic sector, February–April 1979–2010, Clim. Dynam., 39, 3091–3102, https://doi.org/10.1007/s00382-012-1356-6, 2012. a
Talandier, C. and Lique, C.: CREG025.L75-NEMO_r3.6.0, Zenodo [code], https://doi.org/10.5281/ZENODO.5802028, 2021. a
Thorndike, A. S. and Colony, R.: Sea ice motion in response to geostrophic winds, J. Geophys. Res.-Oceans, 87, 5845–5852, https://doi.org/10.1029/jc087ic08p05845, 1982. a
Vanderbecken, P. J., Dumont Le Brazidec, J., Farchi, A., Bocquet, M., Roustan, Y., Potier, É., and Broquet, G.: Accounting for meteorological biases in simulated plumes using smarter metrics, Atmos. Meas. Tech., 16, 1745–1766, https://doi.org/10.5194/amt-16-1745-2023, 2023. a
von Albedyll, L., Hendricks, S., Grodofzig, R., Krumpen, T., Arndt, S., Belter, H. J., Birnbaum, G., Cheng, B., Hoppmann, M., Hutchings, J., Itkin, P., Lei, R., Nicolaus, M., Ricker, R., Rohde, J., Suhrhoff, M., Timofeeva, A., Watkins, D., Webster, M., and Haas, C.: Thermodynamic and dynamic contributions to seasonal Arctic sea ice thickness distributions from airborne observations, Elementa, 10, 00074, https://doi.org/10.1525/elementa.2021.00074, 2022. a
Wang, C., Graham, R. M., Wang, K., Gerland, S., and Granskog, M. A.: Comparison of ERA5 and ERA-Interim near-surface air temperature, snowfall and precipitation over Arctic sea ice: effects on sea ice thermodynamics and evolution, The Cryosphere, 13, 1661–1679, https://doi.org/10.5194/tc-13-1661-2019, 2019. a
Xiu, Y., Luo, H., Yang, Q., Tietsche, S., Day, J., and Chen, D.: The Challenge of Arctic Sea Ice Thickness Prediction by ECMWF on Subseasonal Time Scales, Geophys. Res. Lett., 49, e2021GL097476, https://doi.org/10.1029/2021gl097476, 2022. a
Xu, T., Moore, I. D., and Gallant, J. C.: Fractals, fractal dimensions and landscapes – a review, Geomorphology, 8, 245–262, https://doi.org/10.1016/0169-555x(93)90022-t, 1993. a
Yu, Y., Xiao, W., Zhang, Z., Cheng, X., Hui, F., and Zhao, J.: Evaluation of 2-m Air Temperature and Surface Temperature from ERA5 and ERA-I Using Buoy Observations in the Arctic during 2010–2020, Remote Sens., 13, 2813, https://doi.org/10.3390/rs13142813, 2021. a
Zampieri, L., Goessling, H. F., and Jung, T.: Bright Prospects for Arctic Sea Ice Prediction on Subseasonal Time Scales, Geophys. Res. Lett., 45, 9731–9738, https://doi.org/10.1029/2018gl079394, 2018. a
Zhang, J., Rothrock, D., and Steele, M.: Recent Changes in Arctic Sea Ice: The Interplay between Ice Dynamics and Thermodynamics, J. Climate, 13, 3099–3114, https://doi.org/10.1175/1520-0442(2000)013<3099:rciasi>2.0.co;2, 2000. a
Zhang, Z.-H., Yang, Z., Sun, Y., Wu, Y.-F., and Xing, Y.-D.: Lenet-5 Convolution Neural Network with Mish Activation Function and Fixed Memory Step Gradient Descent Method, in: 2019 16th International Computer Conference on Wavelet Active Media Technology and Information Processing, IEEE, https://doi.org/10.1109/iccwamtip47768.2019.9067661, 2019. a
- Abstract
- Introduction
- Description of the dataset
- Learning the dynamics of sea-ice thickness with neural networks
- Surrogate modeling and evaluation methods
- Numerical results
- Discussion
- Conclusions
- Appendix A: neXtSIM configuration
- Appendix B: Definition of the accuracy
- Appendix C: Neural network architecture
- Appendix D: Surrogate modeling
- Code and data availability
- Video supplement
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Description of the dataset
- Learning the dynamics of sea-ice thickness with neural networks
- Surrogate modeling and evaluation methods
- Numerical results
- Discussion
- Conclusions
- Appendix A: neXtSIM configuration
- Appendix B: Definition of the accuracy
- Appendix C: Neural network architecture
- Appendix D: Surrogate modeling
- Code and data availability
- Video supplement
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References